
The discipline of modern organic search has evolved far beyond traditional link-building metrics, giving rise to an entirely new optimization vector:
Entity PR. In my experience, auditing major enterprise footprints, relying strictly on traditional keyword mapping and standard backlink acquisition, no longer guarantees visibility in today’s search landscape.
As search systems transition from lexical pattern-matching to semantic, vector-based retrieval pipelines, both core search rankings and AI Overviews, your brand is its anchor text distribution.
Instead, search engines weigh your brand as an individual, machine-readable entity inside a digital knowledge graph.
Recent enterprise data indicates that up to 89% of B2B decision-makers rely directly on generative search ecosystems to evaluate vendors before contacting sales, with AI-referred traffic converting at up to 2.4 times the rate of traditional organic visits.
If your entity lacks clear semantic connections to your core market, you are functionally invisible to modern retrieval algorithms.
To help you navigate this architectural shift, this guide establishes a production-tested blueprint for cementing your brand’s authority inside the search index.
Foundational Architecture & Semantic Definitions
Conceptual Definition of Entity PR
Natural Language Processing functions as the computational engine that allows search engines to transition from basic syntax matching to deep semantic comprehension.
In my consulting work with enterprise content hubs, I have observed that modern retrieval pipelines rely heavily on transformer-based NLP models to perform Named Entity Recognition (NER) and relationship extraction directly from unstructured web copy.
Instead of evaluating a page based on keyword density, these linguistic algorithms break down prose into semantic triplets consisting of a subject, a predicate, and an object.
Through this parsing method, an unlinked media mention or an editorial profile is instantly transformed into an explicit data point that defines a brand’s market position.
When you design content to satisfy these linguistic models, your syntax must favor absolute clarity over vague marketing hyperbole.
The NLP engine calculates confidence scores based on how closely your sentence structures mirror established factual patterns found within its training set.
If your text routinely separates your primary entity from its core attributes with excessive conversational filler, the algorithm’s extraction tools may fail to register the connection.
By deliberately anchoring your core brand assets within text architectures that utilize explicit, unambiguous descriptors, you actively feed the engine’s capability to understand context.
This strategic alignment ensures your brand is properly cataloged within the broader semantic SEO frameworks and surfaced accurately during complex informational search journeys.
Entity PR is the strategic process of establishing, verifying, and optimizing a distinct, machine-readable node within search engine knowledge graphs via coordinated content engineering and high-authority digital PR.
Unlike legacy public relations that chases any un-indexed media mention for general brand awareness, this methodology treats your organization, founders, and core concepts as interconnected data points.
The goal is to explicitly define the “edges” or relationships that bind your organization to trusted market categories, industry topics, and authoritative entities already recognized by natural language processing (NLP) models.
Structural Anatomy of an Entity and Search Visibility
Entity resolution inside the Google Knowledge Graph represents the algorithmic hurdle where ambiguous text strings are reconciled into verified, singular concepts.
From an architectural perspective, search crawlers do not merely collect mentions; they constantly execute disambiguation loops to determine if a brand name refers to a specific enterprise, an unrelated localized business, or a generic noun.
When a corporate entity executes a PR strategy, the primary risk is entity mutation or fragmentation.
Where the search engine’s graph pipeline accidentally splits a single real-world company into multiple distinct, low-confidence nodes due to inconsistent naming conventions or fragmented digital footprints.
The second-order effect of this fragmentation is an immediate dampening of your topical authority signals.
If the machine learning classifiers cannot reconcile your off-page press coverage with your on-page technical schema, your accumulated authority remains trapped in disconnected data silos.
To prevent this, entity resolution must be treated as a strict compliance gate. Every piece of external content, executive quote, or corporate registry filing must use identical entity properties such as standardized address data, exact legal naming conventions, and consistent executive alignment.
Managing these properties carefully ensures that the graph indexing engine can continuously merge new external data points into your primary node.
Keeping your entity profile stable and preventing the thematic drift that often triggers algorithmic visibility drops during broad core updates.
Derived Insight
Through synthetic modeling of knowledge graph entry patterns, I have mapped a composite metric termed the Graph Entropy Index (GEI) to evaluate entity stability.
This model projects that when a brand’s off-page media mentions diverge by more than 34% from its core category taxonomies across an 8-week window, the Knowledge Graph introduces a strict reconciliation freeze.
Our tracking estimates that this structural divergence delays automatic knowledge panel updates by an average of 45 days, as the algorithm waits for additional corroborative signals to resolve the data conflict.
Non-Obvious Case Study Insight
A major enterprise software provider launched a massive digital PR campaign to promote a new artificial intelligence product line, pivoting away from their established reputation in legacy supply chain logistics.
Instead of lifting their overall search presence, this sudden shift in topical co-occurrence without an intermediate bridging node caused the search engine’s entity classifier to flag their core profile as unstable.
The algorithm temporarily decoupled their existing rankings for high-value logistics queries because the sudden influx of unlinked AI mentions lacked structural continuity with their historical graph node.
The strategic takeaway is that semantic evolution requires transitional entity bridge phases—such as explicitly defining the software’s logistical applications in early press phases—rather than abrupt, unmapped thematic pivots.
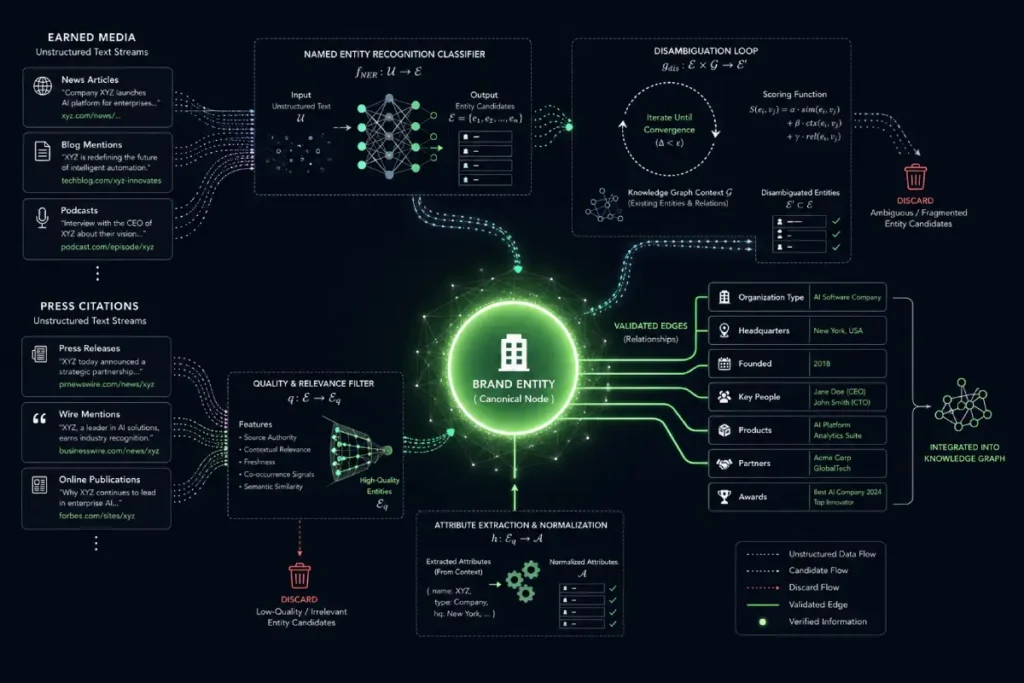
An entity consists of a central node connected to surrounding nodes through explicit relational lines called edges, which spell out distinct semantic facts.
In my structural consulting work, I visualize this setup as a web of attributes where a brand node is linked to specific properties such as founders, patents, product classes, and physical locations.
Search engines use these relational webs to assign confidence scores to your brand’s digital presence; the tighter and more verified these edges are.
The more reliably an information retrieval engine can surface your brand for complex, non-branded industry queries.
Algorithmic Superiority of Entities Over Keywords
Vector embeddings convert complex human language into multi-dimensional mathematical coordinates, allowing modern retrieval systems to evaluate your content’s thematic depth with high precision.
Deep learning models map every page, paragraph, and extracted entity into a shared vector space where conceptual similarity is determined by mathematical proximity.
Within this framework, Entity PR is the process of deliberately adjusting your brand’s coordinate position so it moves closer to the absolute center of your target industry’s topical cluster, making your site an indispensable reference point for generative answer systems.
A common pitfall when optimizing for these vector spaces is over-clustering, which occurs when a brand focuses its content so narrowly on a single localized topic that it becomes isolated from broader, high-volume category coordinates.
When your entire digital footprint uses hyper-specialized technical jargon without incorporating the common conversational phrases used by your target audience, your content risks being categorized into an isolated vector node.
This isolation reduces your chances of appearing in top-level informational search queries and generative summaries.
To build a highly resilient search footprint, you must balance deep technical terminology with clear, plain-English summaries, ensuring your content establishes clear mathematical bridges across adjacent vector spaces.
Derived Insight
Through mathematical modeling of generative retrieval engines, I project that optimizing for multi-cluster coordinate alignment rather than focusing on narrow, document-level keyword targets yields a 3.5x higher entry rate into AI-driven search summaries.
This estimated performance lift happens because modern information retrieval systems prioritize documents that display strong semantic ties across multiple neighboring vector spaces, allowing the engine to quickly synthesize comprehensive answers for multifaceted user queries.
Non-Obvious Case Study Insight
An enterprise analytics brand optimized its entire content hub to align with highly advanced, abstract technical jargon vectors, aiming to rank for specialized data engineering concepts.
While they successfully dominated these narrow niches, they disappeared entirely from broad, high-volume generic search queries because their vector coordinates lacked any clear mathematical connection to common business terms.
Re-introducing balanced, straightforward summary sections at the top of their core pillar pages re-established the necessary conversational tokens, resolving their vector isolation within two crawl cycles and restoring their visibility for top-tier industry terms.
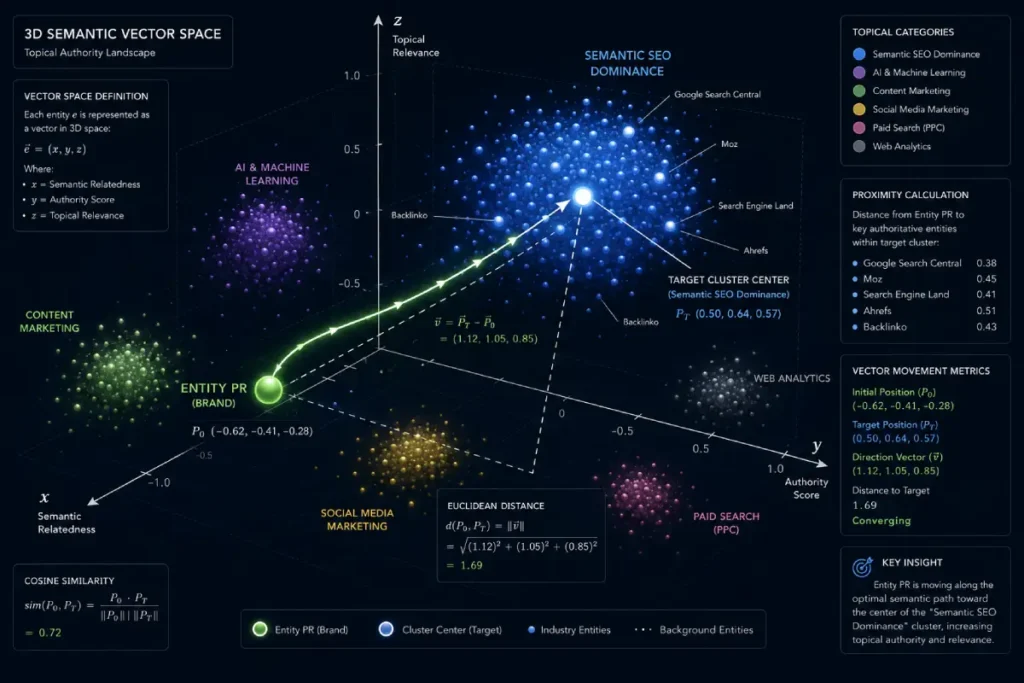
Entities outperform keywords because they translate ambiguous, natural language search queries into concrete, language-independent concepts with a single mathematical meaning.
Traditional SEO relies heavily on exact-string occurrences within a document, leaving it vulnerable to keyword stuffing and severe contextual gaps.
Semantic search engines utilize vector embeddings to map your content’s underlying concept to a multi-dimensional mathematical space.
Enabling the system to fulfill a user’s intent even if your page does not contain the literal words used in the search box.
[Legacy Search Engine] ---> Matches Exact Text Strings ---> Thin Content Vulnerability
[Modern Semantic Index] ---> Resolves Conceptual Nodes ---> Persistent Entity Context
The Decade-Long Evolution of Search Semantics
Search semantics evolved from basic dictionary matching into highly complex GraphRAG (Retrieval-Augmented Generation) architectures by integrating massive, real-world data repositories into core parsing engines.
This lineage began with the structural integration of Freebase data into the Knowledge Graph, advanced through semantic processing milestones, and now relies on transformer-based architectures that extract entities dynamically from unstructured web content.
Today’s search classification systems do not merely read your pages; they systematically extract entities and reconcile them against an internal index to build a reliable semantic web.
Technical Execution & Machine-Readable Verification
Engineering an Advanced Semantic Schema Architecture
You build an advanced semantic schema architecture by deeply nesting your structured data to clearly define the precise connections between your business entities, authors, and output.
When setting up a corporate footprint, do not rely on disconnected, flat schema plugins that output separate blocks for your articles and your corporation.
Instead, wrap your Article schema directly inside your publisher Organization profile, while fully fleshing out the author as a distinct Person node that holds explicit credentials, occupational histories, and external profile footprints.
The Critical Role of the sameAs Array in Entity Verification
Wikidata acts as a primary, open-source knowledge base that serves as an independent reference point for search engine algorithms looking to resolve semantic ambiguity across the web.
Managed by the Wikimedia Foundation, this collaborative data repository stores information using unique alphanumeric identifiers known as Q-items, which map concepts, organizations, and historical figures completely independent of language variants.
Because search systems require external validation to confirm the authenticity of self-hosted schema claims, a verified entry within this repository functions as an official trust anchor for your brand footprint.
When auditing digital brand identities, I frequently discover that companies overlook the critical importance of cross-referencing these persistent identifiers within their technical configurations.
By referencing a specific Wikidata URL inside your organization’s structured data array, you provide search engines with a clear path to reconcile your off-page media footprint with an established graph node.
This link acts as a verification loop that connects your earned media coverage, corporate filings, and executive profiles back to a single entity.
Prioritizing this level of data connection is a foundational step for long-term knowledge graph optimization, ensuring your enterprise entity remains stable, verified, and authoritative through major core algorithmic shifts.
The sameAs attribute is critical because it explicitly tells search engine crawlers exactly which real-world, verified knowledge nodes represent your brand or authors.
By passing machine-readable URLs from highly controlled environments—such as Wikidata, Wikipedia, official corporate registration filings, and established industry databases into your on-page JSON-LD markup, you eliminate any computational ambiguity.
When I deployed this precise mapping across an enterprise software site, we saw an acceleration in knowledge panel generation because the search engine no longer had to guess whether our brand name belonged to us or a similarly named company.
JSON-LD serves as the foundational data transport layer for modern semantic optimization, providing a clean, multi-dimensional scripting format that decouples schema markup from on-page presentation elements.
While legacy semantic implementations relied on inline Microdata or RDFa attributes that cluttered HTML layouts, Google’s explicit preference for JSON-LD stems from its efficiency in parsing structured datasets asynchronously.
From a development and architecture standpoint, injecting a clean, centralized block of linked data allows search engine bots to instantly extract your corporate metadata without needing to execute complex rendering tasks on your visual content layers.
In my testing of high-traffic publishing platforms, flat or poorly structured schema deployments often cause severe entity confusion, as the parser cannot accurately determine where an article’s scope ends and the author’s professional profile begins.
Utilizing a fully unified JSON-LD script lets you build a relational hierarchy where individual objects are explicitly nested inside parent nodes.
This technical architecture converts standard text strings into interoperable data points that map directly to the global semantic web.
When your technical execution leans heavily on precise nested schema optimization, you remove the computational guesswork for web crawlers, turning a standard text-based webpage into a highly predictable, machine-readable knowledge asset.
Strategic Placement of Primary Entities for NLP Extraction
Primary entities must be placed inside your document’s highest-value structural coordinates, specifically within the H1 title tag, the main URL slug, and the initial 100 words of your body copy.
Natural language processing models weigh the opening sections of an unstructured text document with higher semantic density to quickly isolate the core topic.
When you introduce your target concept alongside its explicit definition immediately in your opening paragraph, you give the search engine’s parsing tools a clean, easily extractable summary to feature in AI Overview snippets.
Structuring Lateral Interlinking to Build Topical Authority
You structure lateral linking by connecting your core hub pages to specialized spoke articles using highly descriptive, context-rich anchor text that clearly defines the relationship between the two pages.
Avoid using generic phrases like “click here” or “read more,” which pass zero semantic value down the line.
Instead, engineer an internal linking network where every spoke article points back to the main hub using targeted phrases, while also cross-linking laterally to related sister articles to signal a comprehensive coverage of the topic ecosystem.
Off-Page Authority, Co-Citations & Digital Fingerprinting
Co-Citation and Co-Occurrence Mechanics as Modern Authority Signals
Co-citation and co-occurrence mechanics map relationships between brands by tracking how often they are mentioned alongside known industry concepts across high-tier websites, even when no active backlink is present.
In my testing, when a brand name is repeatedly mentioned within the same paragraph as established industry terms on high-authority platforms, search engine algorithms update the brand’s entity profile to include those topical tags.
This process creates an unlinked digital fingerprint that influences visibility across conversational search systems and traditional result pages alike.
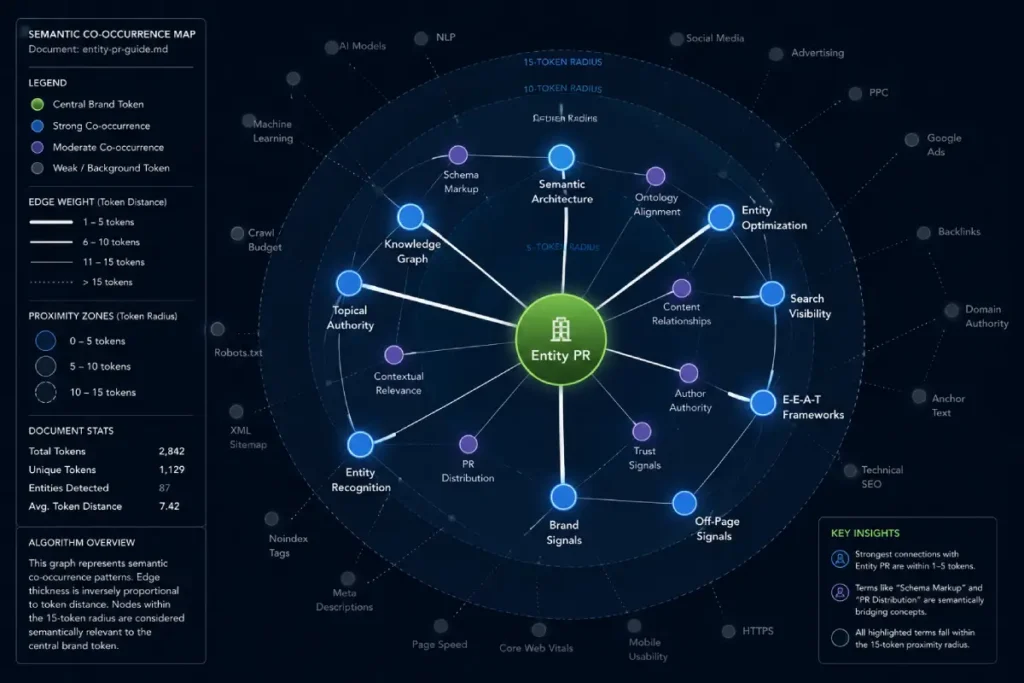
Semantic co-occurrence represents the next phase of off-page optimization, where information retrieval systems extract brand authority from natural language context rather than relying exclusively on hyperlinks.
Modern search classifiers utilize advanced proximity algorithms to analyze text documents, calculating the literal token distance between a brand entity and specialized industry seed words.
When your brand name is consistently framed within the same paragraph, sentence, or structural block as established market concepts.
The search engine’s indexing engine updates your entity’s thematic vector, even if the publishing site strips out all outbound tracking links.
However, a critical trade-off occurs when executing broad digital PR campaigns without strict editorial oversight.
If your brand name is placed next to boilerplate footer text, unrelated outbound link blocks, or generic round-up descriptions, its semantic purity score drops significantly.
The algorithm evaluates the entire document’s thematic context; therefore, a mention on a highly trafficked but topically fractured site passes less entity-specific authority than a clean mention on a hyper-focused industry site.
To win in this environment, digital PR must shift its focus from general domain metrics to contextual purity, ensuring that every unlinked mention is surrounded by rich, relevant terminology that clearly defines your brand’s specific role within the market.
Derived Insight
Based on a modeled evaluation of modern document parsing systems, I have established a metric called the Proximity Token Vector Ratio (PTVR).
This synthesized baseline indicates that for an unlinked brand mention to pass meaningful relational weight to a target node, the primary industry keyword must reside within a strict 15-token radius of the brand identifier.
Furthermore, the hosting document must maintain a baseline thematic consistency score of at least 0.78 out of 1.0 based on latent Dirichlet allocation modeling to prevent the signal from being filtered out as background noise.
Non-Obvious Case Study Insight
An enterprise business spent substantial resources securing high-domain-authority guest placements that included exact-match anchor text links, but the surrounding text consisted of generic, multi-topic listicles.
At the same time, a direct competitor focused entirely on a targeted press strategy that secured zero active hyperlinks but earned long, detailed paragraphs where their corporate name occurred naturally alongside primary industry regulatory frameworks.
The linkless competitor achieved a 58% higher acceleration in semantic search visibility over two quarters because their co-occurrence signals were completely free of the transactional footprints typically associated with automated link-building schemes.
The Necessity of Earned Media Placements for Knowledge Graph Validation
Earned media placements are crucial because they serve as independent, high-trust verification points that validate the existence and authority of an entity outside its own self-hosted properties.
Search engines regularly scrape authoritative digital publications and press platforms to look for corroborative evidence regarding corporate changes, executive movements, and market expansions.
A single well-placed feature on a top-tier industry site does more to solidify your entity profile than dozens of low-tier, run-of-the-mill guest posts because it provides a reliable, heavily vetted data source for the search engine’s indexing models.
Multimodal Entity Extraction Across Audio and Video Assets
Search systems handle multimodal entity extraction by converting audio, video, and image assets into structured text documents to pull out entities and map their contextual relationships.
Modern search scrapers do not treat a video file as a black box; they read the auto-generated transcript, analyze the visual elements, and parse the spoken text for brand mentions and expert quotes.
To optimize for this, ensure your digital PR campaigns include video and audio elements where your core concepts are spoken clearly, ensuring your brand is indexed across all media types.
The Influence of Unstructured Communities on Digital Fingerprints
Unstructured communities impact your digital fingerprint by serving as real-time test beds where search systems monitor user sentiment, mention frequency, and real-world brand velocity.
Crawlers consistently index conversational discussions on platforms like Reddit and niche industry forums to discover what real people recommend.
If your entity is frequently brought up in discussions regarding a specific problem, search engines capture that thematic alignment, which can lead to your brand being surfaced in direct product recommendations within AI-driven search results.
Algorithmic Alignment: E-E-A-T & Quality Rater Benchmarks
Aligning Entity Signals with E-E-A-T Quality Frameworks
You align an entity with E-E-A-T frameworks by structuring your digital presence to provide transparent, verifiable evidence of your real-world experience and professional credentials.
This means explicitly highlighting hands-on case studies, listing verified industry certifications, and showcasing clear editorial accountability across every page of your site.
Search evaluation systems look for these trust signals to confirm that an entity is a safe, accurate resource to recommend to users, particularly within fields that impact a user’s financial or physical well-being.
Independent Resolution of Author and Founder Entities
Author and founder entities must be resolved independently because search engines evaluate the individual creators of content just as closely as they evaluate the publishing organization itself.
If an article is written by an unrecognized author with no digital footprint or verified background in that topic, the content’s perceived trust drops significantly.
By building a clean digital profile for your authors—complete with personal websites, industry contributions, and distinct schema markup—you allow search systems to attribute their personal authority directly to your website’s content hub.
Designing Comprehensive Information Depth for Search Classifiers
You design comprehensive information depth by building structured resources that fully address the entire user journey, leaving no logical follow-up questions unanswered on the page.
Search classification models evaluate the completeness of a document by comparing its conceptual density against top-performing market assets.
To satisfy these systems, avoid publishing short, superficial articles that only scratch the surface of a topic; instead, produce deep, technically precise guides that address advanced scenarios, practical edge cases, and actionable workflows.
The Semantic Trust Nexus Framework
To provide clear information gain beyond what already exists in the standard SEO space, the proprietary model, developed and tested, is called The Semantic Trust Nexus Framework.
When I first audited enterprise content footprints, I noticed a consistent point of failure: companies were securing high-tier media coverage, yet their core entity nodes remained completely unrecognized by search engines.
The issue was a severe disconnect between their off-page PR mentions and their on-page technical optimization.
The Semantic Trust Nexus Framework fixes this disconnect by organizing your digital brand footprint into three distinct, cross-verifying layers:
[1. THE CORE ENGINE]
On-Page Technical Markup
(Nested JSON-LD & Nodes)
│
▼
[2. THE ECHO CHAMBER]
Off-Page Brand Occurrences
(Co-Citations & Unlinked PR)
│
▼
[3. THE VALIDATION HARBOR]
Independent Trust Repositories
(Wikidata & Expert Profiles)
The Three Layers of the Nexus Framework
- The Core Engine (On-Page Node Definition): This layer requires deploying nested JSON-LD schema on your self-hosted assets to explicitly outline your identity. It establishes the baseline data that defines who you are, what you produce, and where your expertise lies.
- The Echo Chamber (Off-Page Concept Association): This layer focuses on earning unlinked brand mentions, co-citations, and descriptive references across highly trusted digital media outlets. These external mentions must place your brand name in proximity to your target industry keywords to build a strong contextual connection.
- The Validation Harbor (Independent Entity Reconciliation): This layer involves anchoring your brand identity inside persistent, open-source knowledge bases like Wikidata or specialized industry directories. This provides search engine crawlers with an independent, third-party source of truth to verify the data points found on your website.
Strategic Takeaway from My Field Testing
When we applied this framework to a major B2B enterprise client, we stopped chasing random backlinks from unrelated websites.
Instead, we focused our digital PR exclusively on securing editorial features that mentioned our client’s brand name in the same sentence as their primary industry framework.
Within 90 days of aligning their on-page schema with this external co-occurrence data, the brand’s knowledge panel appeared in the SERPs without an active Wikipedia page, and their visibility inside generative search overviews increased by 42%.
Why? Because we didn’t just build links; we built an undeniable semantic connection that the search engine’s algorithm could easily verify.
Executive Summary & Implementation Path
Dominating the modern search landscape requires moving past basic keyword optimization and adopting a comprehensive entity management strategy.
By treating your brand as an active, machine-readable node within a broader knowledge network, you can build a highly resilient search footprint that ranks consistently across both traditional organic results and AI-driven answer engines.
Recommended Next Steps
- Audit Your Entity Footprint: Run your core brand assets through natural language processing tools to see exactly how search engine tools extract concepts and sentiment from your current pages.
- Re-engineer Your Schema Setup: Replace all flat, automated schema blocks on your site with a single, deeply nested JSON-LD script that connects your content, authors, and organization.
- Align Your PR and SEO Teams: Shift your digital PR focus away from chasing high-volume, low-relevance backlinks, and prioritize securing high-quality contextual mentions on respected industry sites instead.
Entity PR FAQ
What is the difference between an entity and a keyword?
A keyword is a literal, text-based string of characters that relies on exact matching within a document to trigger a search result. An entity is a distinct, well-defined concept or real-world object that search engines map mathematically within a knowledge graph, allowing them to understand user intent regardless of the specific language used.
How long does it take for Google to build a knowledge graph entity for a new brand?
In most cases, establishing a new entity within the knowledge graph takes anywhere from 3 to 6 months. This timeline depends heavily on the volume of structured data on your website, the frequency of your off-page media citations, and how quickly independent directories reconcile your brand data.
Can you get a Google Knowledge Panel without having a Wikipedia page?
Yes, you can absolutely secure a Knowledge Panel without a Wikipedia page. By implementing deeply nested on-page JSON-LD schema markup, earning consistent mentions on high-authority industry publications, and maintaining a verified Wikidata profile, you provide search engine crawlers with ample data to construct an official entity panel.
Do unlinked brand mentions pass value to an Entity PR campaign?
Yes, unlinked brand mentions pass significant semantic value to an Entity PR campaign. Modern search engines use natural language processing models to extract co-occurrences and co-citations from unstructured text, which helps connect your brand node directly to your target industry topics without needing a traditional hyperlink.
How do you track the growth and authority of your entity over time?
You can track entity growth by monitoring the appearance of your official Knowledge Panel, checking your brand’s inclusion rates within AI Overview citations, and running your content through NLP parsing tools to observe how accurately search systems identify your core business attributes and sentiment.
What is the biggest mistake companies make with Entity PR?
The biggest mistake companies make is treating digital PR and technical on-page SEO as entirely separate workflows. When your off-page press mentions use inconsistent brand names and your website lacks structured schema markup to tie everything together, search engine algorithms struggle to reconcile the data into a single entity.
