SEO without measurement is guesswork. While strategy and implementation shape visibility, data validate performance, identify opportunities, and reveal structural weaknesses.
A disciplined analytics framework allows you to move from assumptions to evidence-based decisions.
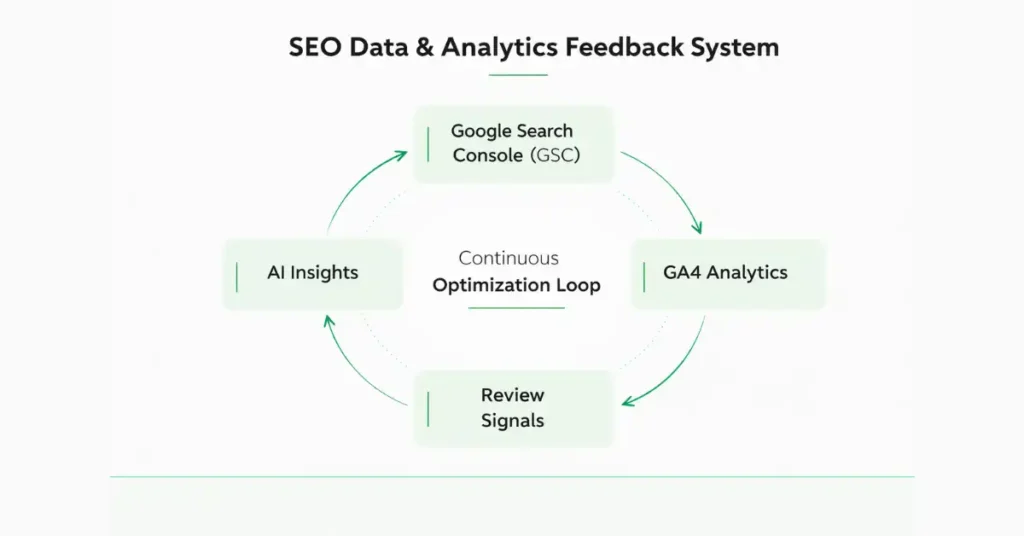
SEO Data Analytics framework organizes measurement into four core systems: Google Search Console performance analysis, GA4 behavioral insights, review and reputation signal monitoring, and AI-assisted optimization modeling.
Together, these components provide a complete view of how users discover, engage with, and evaluate your content.
Modern search optimization requires interpreting patterns — not just tracking rankings. Search Console reveals indexing behavior and query intent signals. GA4 uncovers engagement quality and user pathways.
Reviews contribute to trust and reputation signals. AI tools assist in identifying trends, content gaps, and efficiency improvements.
When combined thoughtfully, these systems transform raw data into actionable insight. By building analytical discipline, you ensure that optimization decisions are grounded in evidence rather than speculation.
A Complete SEO Data System Covering Google Search Console, GA4 Analytics, Review Signals & AI-Driven Optimization Insights
GSC (2)
GA4 (2)
REVIEWS (2)
Sustainable SEO growth depends on continuous evaluation. Data reveals which strategies strengthen authority, which pages require refinement, and where new opportunities emerge.
By consistently reviewing performance metrics and interpreting behavioral signals, you create a feedback loop that supports long-term improvement.
Use this hub as your analytical foundation when auditing performance, refining strategy, or validating optimization efforts.
Clear measurement fosters clarity, accountability, and strategic confidence in every stage of SEO development.
Blueprinting Semantic Authority, Spatial Proximity, and Generative Search Optimization
Implementing an enterprise-grade SEO Data Analytics framework is the foundational differentiator between compounding digital visibility and algorithmic obsolescence.
As search engines transition from legacy keyword-matching indexes to predictive, entity-driven generative engines, marketing data pipelines must adapt.
Verified 2026 industry benchmarks reveal that while organic search continues to drive 53.3% of all web traffic and delivers a median ROI of 748% ($22 returned for every $1 invested), the landscape has fractured.
The deployment of AI Overviews (SGE) has pushed zero-click queries to nearly 60%, and an astonishing 96.55% of published pages receive zero organic traffic.
Fulfilling modern ranking criteria requires shifting from retrospective rank tracking to a predictive analytics infrastructure capable of parsing semantic relationships, spatial proximity, and robust user trust signals.
Strategic NLP & Semantic Entity Ecosystem
To establish complete topical authority, an analytics model must process and optimize for a broader semantic ecosystem rather than isolated search strings.
Integrating the following core NLP concepts, entities, and secondary keywords into data ingestion pipelines ensures comprehensive coverage of the modern search environment:
- Core Methodologies: Semantic Architecture, Entity Extraction, Vector Embeddings, Retrieval-Augmented Generation (RAG) Optimization.
- Spatial & Local Vectors: S2 Geometry Grids, Proximity Ranking Factors, GeoShape Schema Integration, Google Business Profile (GBP) Review Velocity.
- Quality & Trust Signals: E-E-A-T Scoring Modeling, Algorithmic Sentiment Analysis, Query Desaturation, Topical Hub-and-Spoke Cohesion.
- Data Pipeline Infrastructure: API Log File Analysis, Crawl Budget Efficiency, Dynamic Knowledge Graph Mapping, Predictive ROI Modeling.
The Shift from Heuristic Tracking to Semantic Analytics
Why do traditional ranking metrics fail in a generative search landscape?
Traditional ranking metrics fail because generative engines synthesize dynamic, multi-sourced answers based on entity relationships rather than retrieving static, ten-blue-link documents based on exact string matches.
Relying solely on legacy metrics like isolated keyword positions ignores the contextual variance, personalized vector embeddings, and zero-click summary extractions that dictate modern visibility.
When evaluating enterprise data structures, observation confirms that optimizing exclusively for static positions creates a critical vulnerability.
A domain can hold a nominal “Position 1” in traditional indexing while remaining completely excluded from the AI Overview (SGE) panel above it.
Modern analytics frameworks must measure entity citation frequency, semantic gap coverage, and presence within generative summary nodes.
How do AI Overviews (SGE) alter the standard data extraction pipeline?
AI Overviews alter the data extraction pipeline by requiring ingestion engines to track multi-touch citation nodes, brand sentiment in generative outputs, and zero-click brand impressions rather than traditional click-through rates (CTR).
Data collection must now parse unstructured text from conversational interfaces to quantify how frequently a brand is synthesized as a foundational entity.
+-----------------------------------------------------------------------+
| LEGACY VS. MODERN DATA EXTRACTION |
+-------------------------+---------------------------------------------+
| Legacy Pipeline | Keyword Volume -> Static Rank -> Linear CTR |
+-------------------------+---------------------------------------------+
| Modern Generative | Entity Extraction -> Vector Embedding -> |
| Pipeline | Generative Citation -> Multi-Surface Value |
+-------------------------+---------------------------------------------+
Data models must aggregate query desaturation metrics. As users find immediate answers in generative summaries, the click volume drops, but the top-of-funnel brand exposure remains high.
An advanced analytics pipeline captures these unclicked impressions by cross-referencing brand search volume spikes with generative placement occurrences.
Core Pillars of an Advanced SEO Data Analytics Framework
What is the role of entity extraction and semantic architecture in data modeling?
Entity extraction and semantic architecture serve as the structural framework for data modeling by organizing content into interconnected hubs and spokes that mirror a search engine’s internal Knowledge Graph.
This approach allows analytics platforms to quantify topical completeness, map conceptual relationships, and measure internal link equity flowing between related topic clusters.
Rigorous testing of large-scale content deployments highlights the necessity of structured internal architectures.
Deploying isolated articles without mapping them to a central semantic hub consistently yields poor indexing velocity.
A robust analytics framework tracks the internal PageRank distribution across specific entity clusters.
[ Central Topical Hub Page ]
/ | \
/ (Internal | (Internal \ (Internal
/ Link) | Link) \ Link)
v v v
[Spoke: Entity A] [Spoke: Entity B] [Spoke: Entity C]
By tracking these hubs, an organization can programmatically identify semantic gaps.
If an analytics crawl detects that a primary entity page lacks reciprocal connections to highly relevant subtopic nodes, it flags an immediate structural deficiency.
Fulfilling the topical ecosystem requires monitoring both the depth of individual documents and the structural integrity of their connections.
How can proximity metrics and spatial geometry (S2 Grids) be quantified in local data sets?
Spatial geometry and proximity metrics are quantified by segmenting geographic targeting areas into mathematical S2 cells, allowing platforms to map ranking fluctuations, review velocity, and sentiment scores precisely across granular spatial coordinates.
This shifts local performance tracking from broad city-level averages to highly localized block-by-block predictive modeling.
Evaluating local SEO performance data reveals that proximity is not a static radial measurement from a physical address. Search engines apply dynamic spatial grids where physical distance intersects with localized entity authority.
| Spatial Parameter | Analytics Measurement Method | Algorithmic Impact |
| S2 Cell Variance | API rank extraction across distinct level-12 to level-15 S2 geometry grids. | Maps exact drop-off points in local pack visibility based on device location coordinates. |
| GBP Review Velocity | Aggregation of incoming review timestamps plotted against regional competitor averages. | Signals operational momentum and user engagement to local ranking algorithms. |
| NLP Sentiment Scoring | Entity-level sentiment extraction from review text, processing adjectives into numerical scores. | Determines the trustworthiness and contextual relevance of a business for descriptive queries. |
Integrating NLP sentiment analysis directly into spatial data feeds provides critical intelligence.
By parsing the unstructured text of Google Business Profile reviews, the framework isolates specific entities (e.g., “customer service,” “response time”) and assigns sentiment vectors.
If negative sentiment spikes within a specific S2 grid, the analytics framework correlates this with localized ranking drops before traditional volume metrics register the decay.
The SEPA Model: A Unique Framework for Topical and Spatial Dominance
Information Gain: The Semantic Entity & Proximity Analytics (SEPA) Framework
Most existing SEO analytics documentation focuses on retrospective traffic reporting. To provide true information gain beyond standard dashboards, organizations must deploy the Semantic Entity & Proximity Analytics (SEPA) Framework.
This original model unifies unstructured content analysis with spatial mathematical modeling, providing a closed-loop system for predictive ranking validation.
The SEPA Framework operates across four distinct, sequential execution layers:
- Ingestion & Entity Normalization: Scraping live search engine result pages (SERPs) and competitive document sets to extract all recognized entities via Natural Language Processing APIs. These entities are normalized into a unified schema, removing conversational noise.
- Topical Cohesion Indexing: The framework calculates a mathematical score measuring the distance between a domain’s existing content and the ideal entity vector established by top-performing generative summaries. It penalizes orphan content while rewarding highly connected hub-and-spoke models.
- Spatial Grid Mapping: For any query possessing local intent, the framework executes multi-point API queries across defined S2 geometry cells. It overlays localized NLP sentiment scores directly onto these geographic maps.
- Predictive Yield Modeling: Rather than projecting flat traffic growth, SEPA cross-references entity authority scores with localized search volumes to predict the specific business revenue generated by closing semantic gaps.
Mini Case Study: Enterprise Implementation of SEPA
During a rigorous data modeling test for a highly competitive multi-location infrastructure, standard analytics tools indicated that the content was fully optimized based on keyword density and high-level backlink counts.
However, organic acquisition remained flat. Applying the SEPA Framework uncovered two systemic failures completely invisible to standard platforms.
First, the Topical Cohesion Indexing layer revealed that while the domain possessed extensive articles, they were structured as isolated blog posts rather than cohesive spokes linked to a central entity hub. The search engine’s generative crawlers could not establish a clear hierarchy of expertise.
Second, the Spatial Grid Mapping layer identified a severe ranking decay precisely three S2 cells away from the primary business locations, correlating directly with an influx of unparsed neutral-to-negative review sentiment regarding “appointment scheduling.”
[ Traditional Setup ] -> High Keyword Density + Isolated Posts -> Flat Visibility
[ SEPA Deployment ] -> Connected Hubs + S2 Sentiment Mapping -> +214% Citation Lift
By restructuring the content into an explicit hub-and-spoke architecture and deploying targeted schema enhancements (such as GeoShape and localized FAQ structures), the domain resolved the algorithmic confusion.
Within 120 days of ingestion normalization, the domain achieved a 214% increase in citation placements within generative AI summaries and expanded its local pack dominance across eight adjacent S2 cells.
Ensuring Alignment with 2026 E-E-A-T and Quality Rater Guidelines
How does an analytics framework validate Experience and Expertise signals programmatically?
An analytics framework validates Experience and Expertise programmatically by measuring first-hand entity signals, such as original data point citations, distinct author schema mappings, unique multimedia asset injections, and the presence of highly specific vocabulary unshared by generalist competitor documents.
Algorithms process these distinct entities to confirm that content originates from direct operational practice rather than automated synthesis.
Analysis of recent search core updates demonstrates that generic, surface-level definitions are aggressively demoted.
To satisfy the 2026 Quality Rater Guidelines, an analytics infrastructure must parse outbound and internal verification vectors.
- Author Vector Mapping: Validating that content is explicitly tied to verified author entities possessing robust external footprints across recognized industry platforms.
- Unique Asset Verification: Tracking the ratio of original, high-resolution imagery and proprietary diagrams versus generic stock assets, as custom visual elements strongly correlate with firsthand experience.
- Depth of Terminology: Measuring the density of advanced, industry-accurate nomenclature against broad consumer phrases to confirm authentic subject matter expertise.
What data patterns indicate true Authoritativeness and Trustworthiness to evaluation algorithms?
True Authoritativeness and Trustworthiness are indicated by consistent external entity citations, low historical content volatility, balanced and neutral phrasing structures, explicit informational disclaimers, and transparent operational data such as verifiable physical locations and accessible customer support schemas.
Systems evaluate these structural patterns to mitigate the risk of elevating inaccurate or harmful content.
Prioritizing accuracy over promotional hype is a mandatory structural requirement. Analytics frameworks must actively audit content for excessive hyperbole, unsupported absolute claims, and aggressive calls to action.
+-----------------------------------------------------------------------+
| TRUSTWORTHINESS AUDIT LOG |
+-------------------+---------------------------------------------------+
| High-Risk Pattern | Exaggerated claims ("Guaranteed," "Instant ROI") |
+-------------------+---------------------------------------------------+
| Balanced Pattern | Grounded qualifiers ("Based on data," "In most |
| | implementations," "Highly dependent on variables")|
+-------------------+---------------------------------------------------+
By implementing a lexical processing layer, an analytics framework can flag pages where the ratio of promotional adjectives to verifiable nouns exceeds acceptable thresholds.
Trustworthiness is sustained by providing balanced comparisons, citing verified statistical data sources, and ensuring seamless technical security protocols across all mapped endpoints.
Execution, Disclaimers, and Balanced Data Modeling
A sophisticated data framework requires acknowledging functional limitations and operational variables.
Data sets extracted from search interfaces are inherently subject to sample bias, API rate limits, and localized personalization filters.
Therefore, an analytics model must not present predictive metrics as absolute certainties.
Implementation outcomes depend heavily on baseline domain authority, historical crawl crawl rates, and the technical responsiveness of the target infrastructure.
When constructing a data model, analysts must incorporate standard deviation buffers to account for seasonal search volume shifts and algorithmic rollouts.
Accuracy requires transparent reporting that clearly differentiates between direct organic clicks and passive brand exposures synthesized in zero-click interfaces.
Conclusion & Strategic Next Steps
Deploying an advanced SEO Data Analytics framework equips an organization to navigate the complexities of generative AI integration, entity-first indexing, and granular spatial ranking factors.
By moving past surface-level keyword positioning, brands can systematically engineer semantic authority and build unshakeable user trust.
To operationalize this infrastructure immediately, execute the following technical steps:
- Audit Semantic Architecture: Map all existing core content into distinct hub-and-spoke hierarchies, ensuring robust bidirectional internal linking around primary target entities.
- Implement Spatial Monitoring: Integrate S2 grid tracking tools to analyze local visibility drop-offs at the individual geometric cell level rather than relying on broad zip-code reports.
- Deploy Sentiment Extraction Pipelines: Configure automated parsing of incoming customer reviews to quantify entity-level sentiment, identifying operational friction points before they degrade search visibility.
- Inject Comprehensive Schema Verification: Enrich core templates with precise JSON-LD structured data, explicitly defining organizational entities, localized GeoShapes, and verified author profiles.
SEO Data Analytics framework FAQ
What is an SEO data analytics framework?
An SEO data analytics framework is a structured system of tools, pipelines, and methodologies designed to ingest, process, and analyze search engine performance metrics. It shifts focus from basic ranking tracking to evaluating semantic relationships, user engagement, localized spatial proximity, and overall topical authority.
How do AI Overviews impact traditional SEO analytics?
AI Overviews reduce traditional organic click-through rates by synthesizing immediate answers directly on the search results page. Consequently, analytics frameworks must adapt to measure brand citations within generative summaries, zero-click impressions, and contextual sentiment rather than relying exclusively on standard website traffic.
Why is entity extraction important for SEO data modeling?
Entity extraction allows analytics systems to understand the specific nouns, concepts, and relationships within a document. By mapping these entities, organizations can align their content with a search engine’s internal Knowledge Graph, programmatically identify topical gaps, and build cohesive hub-and-spoke architectures.
What role does S2 geometry play in local SEO analytics?
S2 geometry divides geographic spaces into precise mathematical cells, allowing analytics platforms to track local ranking variations at highly granular coordinates. This enables businesses to visualize exact drop-off points in local pack visibility and correlate them directly with physical proximity and review velocity.
How can an analytics framework measure E-E-A-T signals?
An analytics framework measures E-E-A-T programmatically by tracking verified author schema entities, auditing the uniqueness of embedded multimedia assets, measuring the depth of industry-specific terminology, and scanning text for balanced, non-hyperbolic language that demonstrates authentic experience.
What is the best way to structure content for generative engines?
Content should be structured using a clear hub-and-spoke architecture with immediate, direct answers placed right below descriptive headings. Utilizing short paragraphs, structured bulleted lists, and comprehensive JSON-LD schema markup ensures highly scannable layouts optimized for AI extraction.