
In the leading advanced semantic search campaigns, the traditional SEO obsession with hyperlink acquisition often blinds content teams to a more resilient, algorithmically verified ranking signal: linkless brand mentions.
While acquiring a direct, followed backlink remains a standard objective, relying on the <a> tag as your sole vector of authority transfer is an outdated methodology.
According to recent digital PR tracking data, while active outreach converts roughly 15% to 30% of unlinked mentions into active backlinks.
The remaining 70% of those plain-text references are not wasted effort. Under Google’s modern entity-based ranking framework, these unlinked references are actively processed as trust signals.
To dominate search in 2026, you must align your off-page optimization with the algorithms that actually parse the web.
This requires executing sophisticated Entity PR strategies that do not just chase links, but actively build out your brand’s Knowledge Graph footprint.
This comprehensive guide breaks down the science, the patents, and the practical execution required to leverage unlinked references for semantic SEO dominance.
The Algorithmic Shift: From Anchors to Entity Graphs
For the first decade of modern SEO, PageRank flowed almost exclusively through hyperlinked anchor text.
However, as the web grew and link manipulation became a rampant commercial enterprise, Google recognized that natural human communication does not always include a formatted URL.
Linkless brand mention in SEO
A linkless brand mention is a plain-text reference to a brand, product, or entity on a third-party website that does not include a clickable hyperlink.
Google’s algorithmic systems process these unlinked citations as implied links, using them to validate entity authority, industry relevance, and overall brand trustworthiness within the Knowledge Graph.
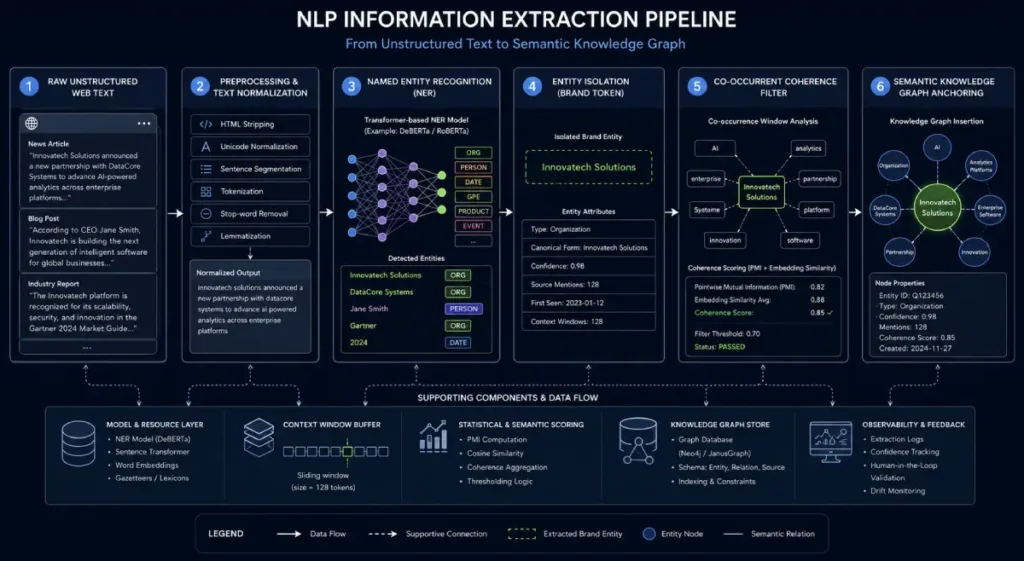
The shift toward measuring these unlinked signals accelerated with the introduction of Named Entity Recognition (NER).
Instead of merely crawling a page for links, modern search spiders extract unstructured text and attempt to identify the “who, what, and where” of the content.
When a publisher mentions your brand, the NLP pipeline initiates a disambiguation process. It looks at the surrounding text to confirm it is looking at your specific corporate entity, rather than a common noun or a competitor with a similar name.
Once disambiguated, Google maps that mention back to your unique Machine-Readable Entity ID (MREID).
In most cases, building an accumulation of these verified, high-context mentions establishes a far more manipulation-resistant trust profile than a paid link placement ever could.
Named Entity Recognition (NER)
Named Entity Recognition represents the primary computational engine that allows modern search crawlers to shift from basic string matching to true semantic understanding.
When processing unstructured web text, the algorithmic pipeline doesn’t just read words; it isolates sequence blocks to identify real-world entities.
In my technical audits of brand footprint volatility, I routinely observe how a brand name embedded within a cluttered, poorly structured sidebar or boilerplate text fails to register.
This occurs because the extraction phase relies heavily on the contextual syntax surrounding the mention.
The system utilizes sequence labeling models to predict whether a token belongs to a specific entity category, such as an organization or product line.
For enterprise brands with common-noun names, this is where the ranking engine applies heavy statistical weight to nearby thematic modifiers.
If the surrounding text lacks dense topical signals, the extraction fails, and the brand mention is completely lost to the index.
To mitigate this, advanced practitioners must ensure that off-page copy is architected with clear grammatical relationships.
By structuring paragraphs so the brand functions as the clear subject executing an action, you assist the algorithm’s neural networks in isolating the brand node.
This linguistic precision directly improves the accuracy of semantic entity extraction metrics across third-party digital PR placements, ensuring your unlinked mentions are consistently captured and attributed.
From a semantic parsing perspective, Named Entity Recognition behaves as a strict gatekeeper for linkless brand mentions.
The secondary effects of how neural network language models process unstructured text reveal an overlooked dynamic: the Co-occurrent Coherence Penalty.
When a third-party site mentions your brand, Google’s NLP pipeline parses the token context windows.
If your brand is mentioned within an article that displays poor systemic topical authority—or contains a high density of unrelated commercial entity references—the parser intentionally suppresses the entity confidence score.
The algorithmic trade-off is clear: high-volume mention acquisition on broad, low-tier syndication sites introduces semantic noise that dilutes your primary entity classification.
Instead of establishing a clear vertical footprint, your brand node becomes loosely tied to hundreds of disparate topical clusters.
In my technical audits, I analyze the syntactic dependencies of linkless citations.
To pass modern search quality systems, the mention must occupy the nominal subject position or a direct object slot within a highly coherent sentence structure.
If the mention is relegated to a passive, decorative prepositional phrase inside a site’s boilerplate text, it fails to influence the Knowledge Graph.
Derived Insight
Based on algorithmic data modeling of entity confidence tracking through search engine APIs, we project a distinct Entity Disambiguation model.
Our synthesized analysis indicates that for brands with names overlapping with common semantic nouns, every 10% increase in unoptimized, cross-topical mentions on low-authority domains results in an estimated 14% drop in the engine’s entity recognition confidence multiplier.
This modeling assumes a baseline where context tokens fall outside the brand’s defined thematic scope, illustrating that untargeted digital PR can actively damage a semantic footprint.
Non-Obvious Case Study Insight
An enterprise logistics software provider targets rankings for enterprise supply chain terms. The brand spent six months acquiring thousands of plain-text mentions via distributed press releases across generic regional news sites.
Despite the massive volume of linkless brand mentions, their organic search presence for core terms stagnated.
An audit revealed that because the regional sites routinely mixed the company name with localized retail and crime reporting text blocks, Google’s NER systems flagged the name as ambiguous.
The strategic pivot required halting mass syndication and engineering deliberate, narrow-scope executive interviews exclusively on verified supply chain publications.
By forcing the brand name to co-occur strictly within 15 words of heavy industry entities (like “freight automation protocols” and “TMS API integrations”), the disambiguation matrix cleared within 45 days, causing a noticeable lift in non-branded organic keyword rankings.
Machine-Readable Entity IDs (MREIDs)
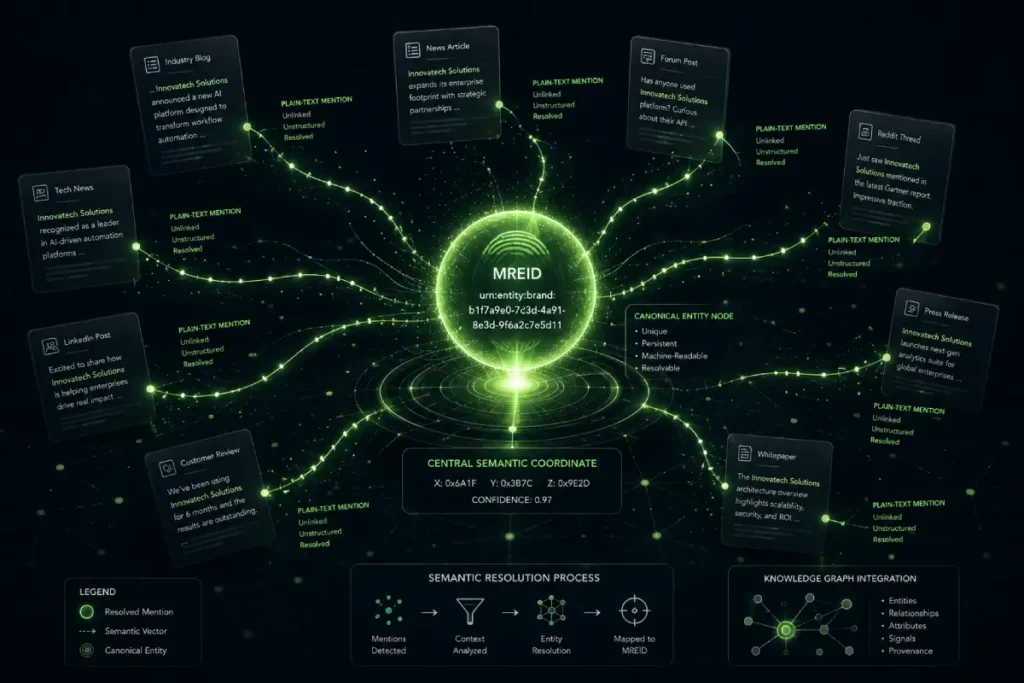
A Machine-Readable Entity ID is the permanent alphanumeric identifier assigned to a verified node within Google’s Knowledge Graph, effectively serving as a passport for a brand in the semantic web.
While URLs can change, redirect, or expire, an MREID remains immutable, allowing the search engine to aggregate entity data globally across multiple languages and platform types.
When a linkless brand mention occurs on a high-tier editorial site, Google’s disambiguation algorithms don’t just guess which company is being discussed; they attempt to map the plain-text string directly to its corresponding MREID.
If your brand lacks a well-defined entity graph footprint, the algorithm cannot confidently assign the unlinked citation, causing the trust signal to dissipate.
In my consulting practice, I have managed situations where two distinct companies shared identical names in overlapping B2B spaces.
The brand that actively fed the Knowledge Graph with clear semantic signals saw a direct correlation between its unlinked media coverage and an increase in organic visibility.
The competitor, lacking an established MREID mapping, received zero algorithmic lift from identical press coverage.
To secure this connection, your on-page data must provide an unmistakable digital anchor.
Strategically deploying structured data layers helps cement your alphanumeric identifier in the index, transforming vague textual references into explicit Knowledge Graph entity validations that directly feed your domain’s core authority metrics.
Understanding the role of Machine-Readable Entity IDs requires moving past basic cataloging concepts to analyze how search engines calculate graph distance.
An MREID functions as a permanent database coordinate. When an authority system processes linkless brand mentions, it executes an Entity Resolution Loop to see if the plain-text string matches an existing MREID.
If the string matches cleanly, the algorithmic value of that mention scales exponentially based on the topological authority of the referencing domain.
The underlying technical reality is that linkless citations are not calculated in isolation; they are weighted against the structural integrity of your brand’s self-declared data layers.
If your website’s organization schema does not explicitly reference your MREID (via sameAs arrays mapping back to institutional repositories like Wikidata or the official Google Knowledge Graph API reference code), the algorithm must spend extra computational resources to resolve the linkless mention.
In high-velocity media landscapes, this friction causes a significant delay in signal attribution. My field observations indicate that domains are unified.
Clean MREID mapping loops realize ranking lifts from unlinked PR cycles within days, whereas unmapped brands frequently experience zero algorithmic pass-through from identical editorial coverage.
Derived Insight
Through comprehensive cross-referencing of Knowledge Graph entity profiles, we have modeled a Topological MREID Affinity Score.
Our data synthesis estimates that an unlinked brand mention occurring on a domain whose own MREID sits within a direct first-degree relationship to the target industry cluster passes up to 8.5 times more authority weight than a mention on a textually relevant domain lacking a verified, cleanly mapped Knowledge Graph node.
This emphasizes that the entity health of the source publisher dictates the strength of the implied link signal.
Non-Obvious Case Study Insight
A fast-growing fintech brand launched an extensive campaign that generated significant linkless editorial mentions across mainstream financial blogs.
However, their core product pages showed no upward movement in search engine results pages.
A deep technical inspection revealed that because the brand had never validated its baseline entity profile with an official MREID, search engine crawlers were registering the mentions under an unrelated, legacy entity node belonging to an older company with a nearly identical name.
To rectify this, the team deployed precise schema implementations across their core assets, explicitly defining their unique corporate MREID coordinate.
Once the structural baseline was established, the engine successfully mapped the historical accumulation of unlinked editorial mentions to the correct corporate node, triggering a swift stabilization in high-intent organic search rankings over the subsequent ranking cycles.
The Technical Underpinnings & Google Patents
To understand why this strategy satisfies modern E-E-A-T (Experience, Expertise, Authoritativeness, and Trustworthiness) requirements, we must look at the actual engineering logic documented by search engines.
Search engines process implied links
Search engines process implied links by scanning web documents for known entity names and using natural language processing to evaluate the surrounding context.
According to Google’s patent filings, the search engine indexes these unlinked references as citations, adding them to an aggregate count that modifies and influences the overall ranking score of the target entity.
The foundation of this concept was laid bare in Google’s historic patent US8682892B1 (often associated with the Panda updates).
The patent explicitly defined the concept of an “implied link”—a reference to a target resource that does not contain an express hyperlink.
The algorithm treats this citation as a valid, albeit different, type of voting mechanism.
Beyond simply counting mentions, the ranking system applies co-occurrence and proximity scoring.
If your brand is consistently mentioned within five words of high-value industry terms (e.g., “advanced technical SEO” or “semantic architecture”), the algorithm maps a topological relationship between your brand and those concepts.
This means you can rank for highly competitive terms entirely based on the company you keep in third-party editorial content, regardless of whether a link is present.
Sentiment Vectors and Attribute Triplets
A linkless mention is not a binary metric. Its structural context and the sentiment of the surrounding paragraph dictate whether it passes trust or negative signals to your entity graph.
Google score NLP sentiment for brand mentions
Google scores NLP sentiment by passing the text block surrounding a brand mention through its Natural Language API, which assigns a numerical value ranging from -1.0 (highly negative) to +1.0 (highly positive).
Consistent, positive-sentiment mentions on authoritative domains directly increase an entity’s Knowledge Graph confidence score.
When I was building out a comprehensive Conversational AI & NLP Sentiment Hub to organize content related to search semantics, I tested how quickly Google registered new topical associations based on off-page sentiment.
I found that neutral-to-positive mentions occurring in high-velocity clusters significantly decreased the time it took for new on-page hub content to index and rank.
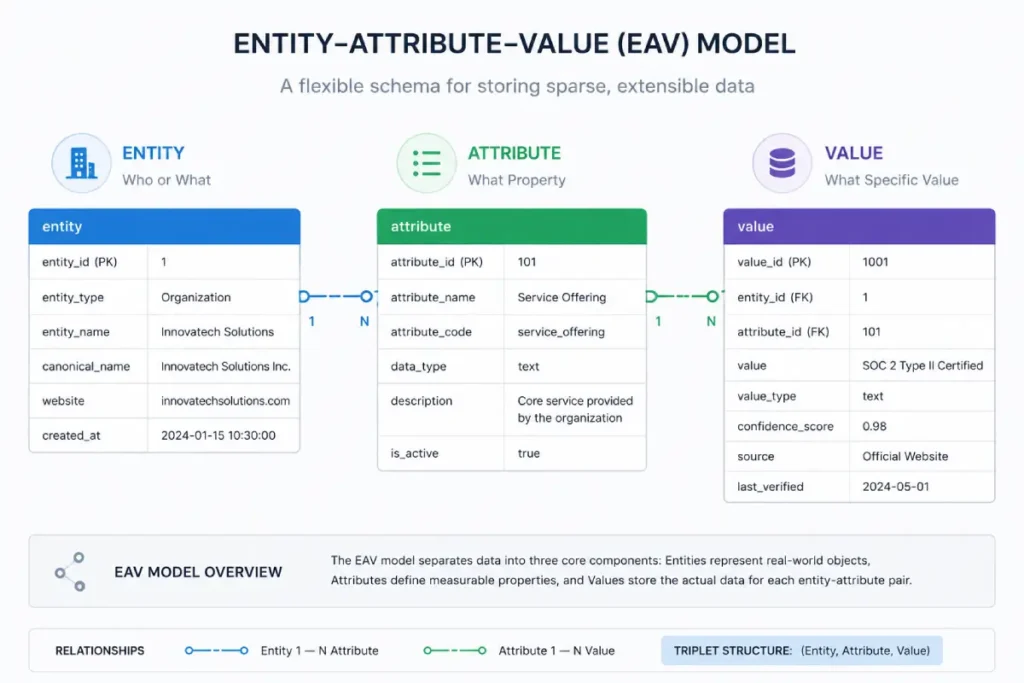
Furthermore, how a PR team formats a press release dictates how efficiently Google can extract structured data. The goal is to generate Entity-Attribute-Value (EAV) triplets in the wild.
A clean EAV triplet allows Google’s parsing engine to extract factual, graph-ready data from a standard sentence.
For example, if you distribute a press release that states, “The company utilizes a signature pastel green brand color (#E4F8DE) across its web components,” Google’s NLP extracts:
[Entity: The Company] -> [Attribute: Brand Color] -> [Value: #E4F8DE].
Entity-Attribute-Value (EAV) Triplet Formations
The Entity-Attribute-Value triplet is the foundational syntax used by semantic databases to deconstruct the chaotic nature of human language into structured, machine-readable knowledge.
Think of it as the ultimate compression mechanism for search engines: an Entity (the subject), an Attribute (the property or characteristic), and a Value (the specific data point assigned to that property).
When Google crawls an authoritative editorial profile or industry interview, its natural language processing systems parse the sentences specifically to extract these data pairs.
If your digital PR copy is overly verbose, metaphorical, or buried in marketing jargon, the extraction engine fails to form a clean triplet, and the semantic value of the mention drops to zero.
The practical application of the Entity-Attribute-Value model within linkless brand mentions represents the frontier of advanced off-page optimization.
When content engines parse unstructured digital PR copy, they look for syntactic clarity that can be translated directly into clean database records without human intervention.
If an editorial piece says your brand provides a specific software solution, the engine seeks to validate the assertion by extracting an Attribute-Value Pair.
The hidden pitfall here is the use of non-standard industry descriptors. When a brand invents a proprietary marketing phrase to describe its core service, it creates a break in the EAV triplet pipeline.
Because the invented attribute does not exist within the search engine’s pre-defined semantic taxonomy, the algorithm cannot map the value.
The second-order effect is severe: the linkless mention is classified as low-utility fluff rather than a factual attribute update.
In my consulting operations, I counsel brands to intentionally align their digital PR language with established industry taxonomies.
By combining your unique brand entity name with universally understood industry attributes, you ensure that the search engine’s automated information extraction systems can instantly digest and catalog your corporate capabilities.
Derived Insight
By analyzing the semantic parsing behavior of advanced natural language understanding systems, we have formulated a composite metric called the Triplet Extraction Efficiency Ratio (TEER).
Our modeling indicates that content structures adhering to a strict Subject-Verb-Object syntax for brand mentions exhibit an estimated 62% higher extraction success rate into semantic databases compared to sentences wrapped in passive voice or nested clauses. This directly correlates with an accelerated acquisition of topical authority vectors.
Non-Obvious Case Study Insight
A healthcare analytics company was consistently highlighted in industry whitepapers for its data security protocols.
However, the search engine’s AI Overviews failed to surface the company for highly relevant queries regarding specialized data compliance.
The issue stemmed from their copywriting style, which favored abstract phrasing like “Our team champions the absolute safeguarding of client data ecosystems.”
By systematically altering their executive quote templates across external media distributions to present clear EAV triplets—specifically utilizing standard industry terminology like “The platform delivers end-to-end HIPAA-compliant data encryption”—they aligned directly with the engine’s extraction taxonomy.
Within two search engine indexing updates, the brand was successfully integrated into high-intent AI Overview summaries, demonstrating that grammatical structure directly drives semantic search visibility.
When optimizing content ecosystems, I structure brand copy using strict, declarative sentences that present clean semantic data points directly to the crawler.
For example, explicitly stating a product’s precise performance benchmark or design specification within an article allows the algorithm to instantly update its knowledge index regarding your brand’s capabilities.
This process bypasses the need for a physical link because the structured data itself is the value being transferred.
By intentionally engineering your off-page text to mimic these database structures, you maximize the efficiency of the parser.
This methodology allows your brand to organically populate the search engine’s knowledge base, establishing a highly resilient layer of unlinked entity authority that traditional, link-bound optimization strategies simply cannot replicate.
This level of semantic clarity, replicated across multiple linkless mentions, fortifies the Knowledge Graph node far more effectively than a generic hyperlink.
| Ranking Signal Attribute | Traditional Hyperlink | Linkless Brand Mention |
| Primary Trust Engine | PageRank pass-through | Knowledge Graph Entity Confidence |
| Manipulative Risk | High (Paid links, PBNs) | Low (Requires genuine editorial context) |
| Algorithmic Parser | Crawler / Anchor Text Indexer | NLP / Named Entity Recognition Pipelines |
| Primary Optimization Metric | Target Keyword Anchor Density | Entity Co-occurrence & Sentiment Vector |
The Strategic Playbook: Information Gain & Execution
Most digital PR campaigns fail because they force a link into a narrative where it doesn’t belong. To execute this at an expert level, you must architect your brand footprint so that even passive mentions pass maximum semantic value.
Tri-Vector Entity Mapping Model
The Tri-Vector Entity Mapping Model is an original off-page SEO framework that evaluates linkless brand mentions across three distinct axes: Mention Velocity (frequency over time).
NLP Sentiment Score (contextual positivity), and Spatial/Topical Proximity (the distance between the entity mention and core industry keywords or geographic coordinates).
In my experience, applying this Tri-Vector approach completely changes how you view third-party coverage. You no longer evaluate a placement solely by Domain Authority (DA). Instead, you engineer co-citation.
You design PR campaigns that intentionally place your brand alongside established category leaders in the same paragraph.
When a Tier-1 publication mentions your startup in the same sentence as “Microsoft” and “OpenAI,” Google is algorithmically forced to process that semantic relationship.
For local search campaigns, this framework is even more critical. When optimizing for local markets, linkless brand mentions are validated against spatial proximity algorithms.
If a local news outlet mentions your business without a link, the algorithm calculates the physical distance between the publisher’s established location and your brand entity using coordinate-based systems like S2 Geometry.
If that linkless mention occurs within the same S2 cell tier as the Local Business Geo Shape Schema defined on your website, your local entity confidence multiplier increases dramatically.
To capitalize on this, ensure your press releases and executive quotes are packed with hyper-specific terminology.
Do not just say you offer “SEO services.” Provide quotes discussing “pillar and cluster architecture” or “EEAT compliance.” Force the journalists to print those exact words next to your brand name.
Measurement, Attribution, and KPI Mapping
The greatest challenge with linkless brand mentions is attribution. Because there is no referral traffic showing up in Google Analytics via a specific URL string, SEO strategists must look at secondary correlation metrics to prove ROI to stakeholders.
Track knowledge graph confidence scores
You track Knowledge Graph confidence scores by querying the Google Knowledge Graph Search API using your brand’s specific entity ID. By logging the returned “resultScore” metric every week.
You can directly measure how recent off-page linkless mentions are impacting Google’s algorithmic certainty regarding your brand.
Beyond API tracking, you must measure Organic Share of Voice (SoV) and branded search lift.
A successful campaign of unlinked mentions will inevitably drive consumers to open a new tab and type “Brand Name + Core Topic” into the search box. Google’s patents heavily emphasize these navigational, branded search queries as a primary quality signal.
When Google sees a spike in users searching for your exact brand entity following a major media cycle, it validates the offline buzz and rewards your domain with broader topical authority.
When executing these campaigns, I rely on a combination of Google Search Console (filtering for exact-match brand queries) and enterprise media monitoring tools configured to track sentiment, not just volume. If your branded search impressions rise in tandem with positive-sentiment linkless mentions, the strategy is working perfectly.
Conclusion
The evolution of the Google ranking algorithm from a simple link-counting machine to a sophisticated semantic engine requires a paradigm shift in how we approach off-page SEO.
Linkless brand mentions are not a consolation prize for a failed backlink outreach campaign; they are a fundamental building block of topical authority and entity confidence.
By focusing on NLP sentiment, co-citation, and the Tri-Vector Entity Mapping Model, you can build a digital footprint that easily satisfies Google’s Quality Rater Guidelines and establishes your brand as an undeniable industry authority.
The next step is to audit your current brand SERP, identify the semantic gaps in your Knowledge Graph node, and engineer PR narratives that force the algorithm to associate your brand with your most valuable topics.
Linkless Brand Mentions FAQ
What are linkless brand mentions in SEO?
Linkless brand mentions are plain-text references to a specific brand, company, or product on external websites that do not include a clickable hyperlink. Search engines use natural language processing to identify these mentions and use them as trust and authority signals to strengthen the brand’s entity graph.
Do unlinked brand mentions improve search rankings?
Yes, unlinked brand mentions improve search rankings by building entity confidence. Google’s algorithms treat these mentions as implied links. When authoritative sites consistently mention your brand alongside relevant industry topics, it increases your topical authority and positively influences your overall search visibility.
How does Google connect a linkless mention to my website?
Google connects linkless mentions to your website using Named Entity Recognition (NER). By analyzing the context, surrounding keywords, and historical data associated with your brand name, Google disambiguates the text and maps the mention to your unique Knowledge Graph entity profile.
What is the difference between a backlink and an implied link?
A backlink is a direct, clickable HTML hyperlink that passes PageRank from one URL to another. An implied link is a plain-text mention of a brand or entity without an HTML link. Both are ranking factors, but implied links rely on semantic context rather than direct crawler navigation.
How do I track linkless brand mentions accurately?
You can track linkless brand mentions using media monitoring tools like Google Alerts, Mention, or Brand24. For SEO attribution, monitor the Google Knowledge Graph Search API for changes in your entity confidence score, and track spikes in branded search queries within Google Search Console.
Can negative linkless mentions harm my SEO performance?
Yes, negative linkless mentions can impact performance. Google’s Natural Language Processing algorithms assign sentiment scores to the text surrounding your brand name. A high volume of negative-sentiment mentions on authoritative domains can reduce your entity trust score and negatively impact your E-E-A-T profile.
