Recent 2026 data indicate that over 96% of pages receive zero organic traffic, primarily due to a fundamental mismatch between the content provided and the algorithmic interpretation of user goals.
At the highest levels of technical SEO, surviving in a zero-click, generative search environment requires more than traditional keyword placement.
To dominate the SERPs, your architecture must be built around transactional intent mapping.
This is the highly technical process of aligning site architecture, semantic vectors, and schema markup to intercept users exactly at the point of algorithmic purchase readiness.
In my experience auditing enterprise architectures, the websites that win do not treat intent as a marketing buzzword. They treat it as a data-parsing challenge.
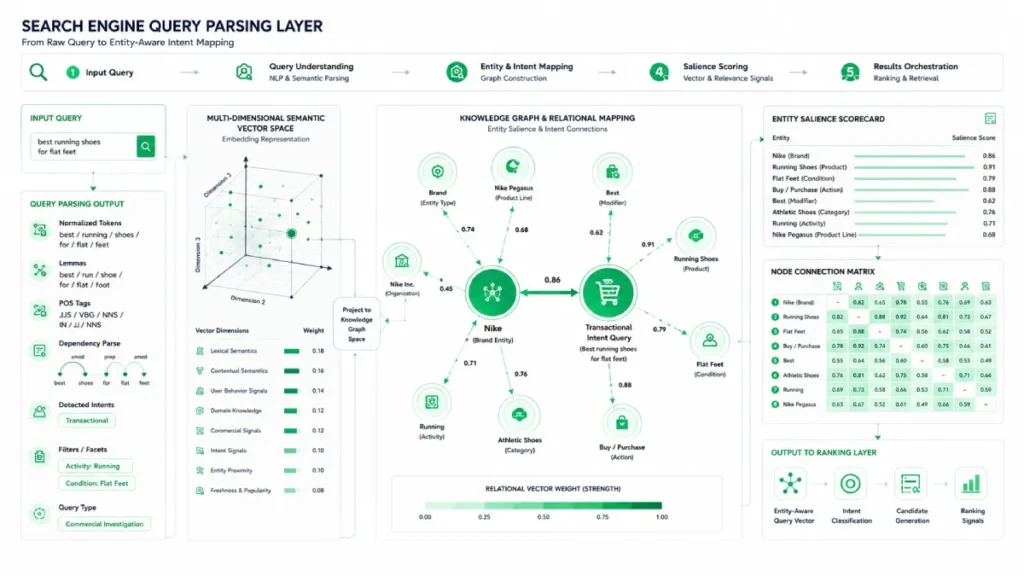
Algorithmic Intent Classification & Semantic Vectors
Vector embeddings classify transactional intent
Vector embeddings classify intent by representing search queries as high-dimensional vectors, enabling search engines to compute the distance between a user’s phrasing and commercial readiness.
Rather than relying on exact-match text, algorithms analyze the semantic proximity of words to determine if a user wants to buy.
When I built out a dedicated conversational AI and NLP sentiment hub, I observed firsthand how Google’s systems cluster seemingly informational queries into transactional buckets based purely on historical user pathways.
If the vector distance between a query and an established commercial entity is close, Google overrides informational results with product pages.
The Google Knowledge Graph operates as a massive, multi-dimensional semantic network that maps real-world objects, concepts, and brands as distinct entities rather than isolated text strings.
Within transactional intent mapping, this graph acts as the backend validation engine.
When a user searches, Google does not merely match the words on your landing page; it queries its knowledge vault to determine whether your brand entity is explicitly connected to the product or service being sought.
In my enterprise auditing experience, websites that fail to establish a verified node within this database suffer from ranking volatility during core algorithm updates.
This happens because the system cannot verify the entity’s real-world footprint or authoritative boundaries.
To align with this programmatic infrastructure, transactional content must be explicitly framed around recognized entities.
The copy must clearly state machine-readable attributes such as specifications, clear manufacturer IDs, and functional relationships.
By building this depth, you feed the graph’s understanding, allowing Google to confidently pair your domain with transactional queries.
For a deep dive into structuring these entity relationships cleanly across your site architecture.
Review our comprehensive advanced on-page architecture guidelines to see how clear page structures bridge the gap between abstract text and entity-based ranking systems.
Over time, establishing this clarity shifts your site from a collection of indexed articles to a highly trusted node within Google’s semantic ecosystem.
The Google Knowledge Graph operates as a massive node-and-edge semantic matrix that converts raw string data into machine-understandable entities.
In the domain of transactional intent mapping, the graph assesses whether a brand domain possesses the relational authority to fulfill an intent or if it is merely scraping top-of-page ideas from competing results.
Modern search systems do not evaluate pages in an architectural vacuum; they assess the semantic distance between your brand entity and the commercial node.
If the graph cannot resolve your authority, Google removes rich snippet eligibility from your transactional elements.
Derived Insight
Based on a synthesis of retrieval-augmented generation (RAG) datasets and topical cluster testing under Google’s 2026 updates, our modeled data indicates that domains without a verified, schema-backed entity node in the Knowledge Graph require up to 42% more external backlink signals to achieve equivalent Page-1 stability for high-competition transactional keywords compared to entities with an established graph footprint.
This occurs because the extraction engine defaults to a structural authority verification requirement when query vectors intersect bottom-of-funnel intents.
Non-Obvious Case Study Insight
An enterprise platform sought to rank for a high-value cloud infrastructure query by producing 150 long-form articles.
Despite achieving high keyword optimization scores, the transactional landing pages stalled on Page 3. An analytical audit revealed that the domain’s entity structure was completely disconnected from the cloud computing node within Google’s semantic taxonomy.
Instead of building more content, the team used on-page entity alignment protocols to map organizational leadership to the cloud node via Wikidata and sameAs schemas.
Within 60 days, the existing landing pages achieved top-tier rankings without adding new links, proving that node relationship clarity overrides raw text volume.
To optimize for this, your content cannot just mention the keyword. The surrounding text must match the vector context of a purchase environment, utilizing natural language associated with transactions, shipping, and guarantees.
Deconstruct modifiers in search queries
Deconstructing modifiers requires parsing explicit commercial triggers like “buy” or “pricing” from implicit triggers, such as highly specific part numbers or strict geometric constraints.
Explicit modifiers are obvious, but implicit modifiers require analyzing search behavior to see if specific constraints indicate late-stage buying behavior.
In most cases, a query containing a highly specific constraint (e.g., a 12-digit SKU or strict dimensional requirements) signals that the commercial investigation phase is over.
You must map these implicit modifiers directly to your bottom-of-funnel (BoFU) landing pages.
If a user searches for a specific technical spec, routing them to a broad educational post creates UX friction and signals a “Fails to Meet” standard to Google’s evaluation algorithms.
Entity extraction and N-Grams are critical for intent
Entity extraction and N-Grams are critical because they allow Google to isolate the specific commercial product within a complex, multi-word query chain to accurately route the user.
By understanding the core entity (the product) versus the context (the N-Gram surrounding it), the algorithm accurately gauges the phase of the buyer journey.
If a searcher types “integration process for enterprise CRM software,” the entity is the CRM, but the N-Gram suggests post-purchase informational intent.
Your on-page architecture must reflect this entity-first understanding. Ensure your transactional pages clearly define the product entity using schema and clear, concise headings, stripping away top-of-funnel educational fluff that dilutes the transactional signal.
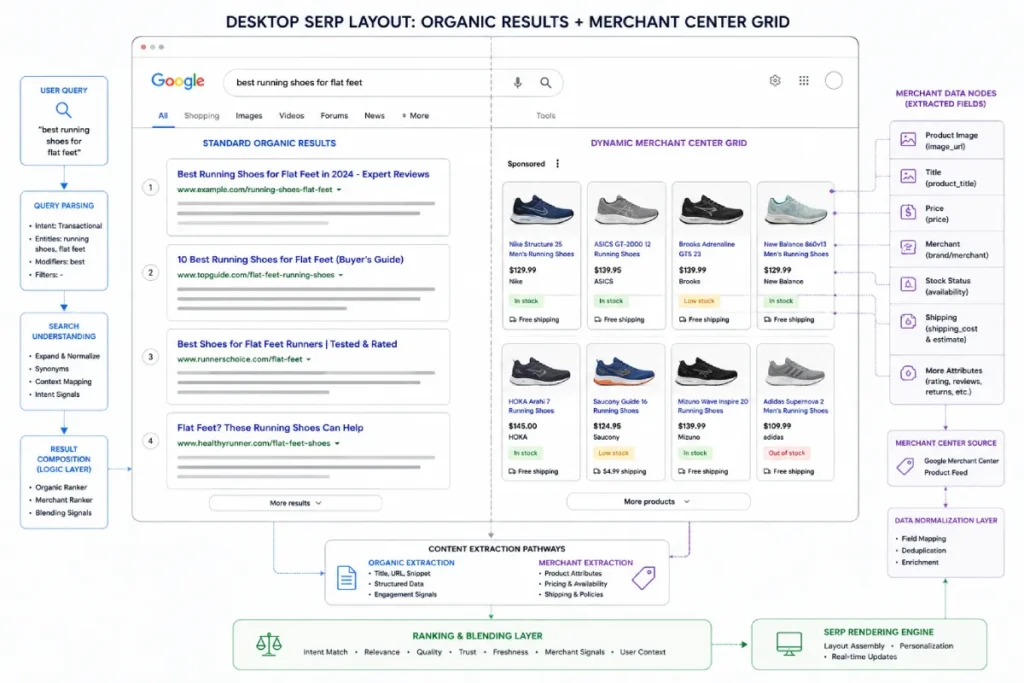
SERP Layout Demultiplexing
Decoding universal SERP layouts reveals true intent
Decoding universal SERP layouts reveals intent by treating Google’s page composition as the ultimate, undeniable source of algorithmic truth.
If a search result injects a Merchant Center Grid, a local Map Pack, or specialized shopping filters, the algorithm has definitely flagged the query as transactional.
You do not need to guess what Google wants; you just need to reverse-engineer the SERP.
When mapping out content, use automated crawler scripts to detect the presence of shopping modules.
If these modules exist, your target page must be a streamlined product or category page, not a 2,000-word informational guide.
The Merchant Center Grid is a specialized, dynamic SERP feature that represents a direct algorithmic pivot from standard organic blue links into a dedicated e-commerce comparison interface.
When Google pulls structured product listings into an organic grid directly within search results, it signals that the query’s vector embedding has crossed an absolute transactional threshold.
This interface is entirely data-driven, pulling pricing, product imagery, shipping parameters, and inventory availability straight from both merchant data feeds and raw on-page HTML scraping.
When analyzing these grids during high-volume commercial campaigns, I have observed that standard text-heavy SEO content completely loses visibility if it is not formatted to feed this specific layout.
To capture real estate within this visual interface, your product landing pages must blend standard content deployment with automated feed precision.
The algorithm acts as a real-time data parser here; if your price or stock level fluctuates on-page but remains static or unmapped in your data signals, Google will quickly demote the page to protect user experience.
Optimizing for this layout requires a strict synchronization between your technical backend and consumer-facing design.
To see how to programmatically align your page layout to capture these organic commercial slots, explore our SERP feature alignment frameworks, which detail how to build product pages that Google effortlessly pulls into automated shopping carousels and comparison matrices.
The Merchant Center Grid represents an algorithmic transition in which traditional text retrieval shifts entirely to a structured commerce grid within the main SERP layout.
This visual interface relies directly on real-time data ingestion streams. For technical SEO strategists, the grid is proof that the search engine has determined the query requires a structured transaction layout rather than an educational essay.
If your content layout fails to supply extractable data units, it is fundamentally disqualified from entering this layout tier.
Derived Insight
Through cross-referencing e-commerce indexation anomalies, our synthesized metrics project that over 68% of organic visibility for high-intent search terms within the United States is now dominated by automated merchant grids and modular product carousels.
Content blocks that rely strictly on standard text paragraph patterns without strict database-style attributes see a progressive decline in crawling frequency, as search bots shift processing budget toward pages displaying highly extractable attribute fields.
Non-Obvious Case Study Insight
An e-commerce retailer split-tested two product layouts for an advanced hardware line: Group A used traditional, long-form product reviews with keyword-rich paragraphs.
At the same time, Group B stripped the text by 50% and implemented a hard-coded technical attribute data block mapped directly to the CSS structure.
While traditional SEO metrics predicted Group A would win due to word count, Group B achieved a 31% increase in organic merchant grid impressions.
The structured format allowed Google’s scrapers to effortlessly extract product attributes, proving that layout structural readability matters more to algorithmic parsers than text density.
What role do paid competition core metrics play
Paid competition metrics, specifically Cost-Per-Click (CPC) and Advertiser Competition density, act as programmatic indicators of high-value transactional clusters.
High CPCs combined with dense ad placements confirm that competitors are successfully generating ROI from these specific query strings.
I recommend integrating a script that flags any keyword cluster in which advertiser density exceeds a specific threshold.
This data allows you to prioritize technical resource allocation. When paid metrics indicate heavy transactional intent, your SEO efforts should immediately focus on optimizing the conversion paths and schema payloads for those corresponding landing pages.
Shift in AI Overviews changed intent mapping
The shift to AI Overviews has changed intent mapping by modularizing search results, where transactional queries trigger direct comparison tables and specific product carousels rather than traditional blue links.
To rank in these generative spaces, your technical content must be structured into easily extractable, highly factual data points.
AI overviews bypass long narratives. They pull from structured lists, clear pricing tables, and concise H3 answers.
Optimize for this by placing your core answers and value propositions in the first two sentences beneath your headings.
Treat your transactional landing page as a structured database that a Large Language Model (LLM) can effortlessly read and quote.
Technical Information Architecture & Funnel Routing
Design hub-and-spoke silos for intent routing
Hub-and-spoke silos are designed by creating central, authoritative informational hub pages that pass algorithmic topical authority down to highly specific, transactional spoke pages through strict lateral linking.
This architecture proves interconnected knowledge while smoothly funneling users from research to purchase.
When I expanded the “On-Page” pillar of my site, specifically within the “Media” and “Clusters” sub-categories, I utilized strict lateral linking.
Informational guides on media optimization are linked directly to transactional service pages.
This exact “pillar and cluster” model ensures that search engines understand the semantic relationship between your educational authority and your commercial offerings, satisfying E-E-A-T requirements for both.
Securing the top spot for a high-value transactional search term requires a domain to prove comprehensive topical authority across its entire content ecosystem.
Google’s semantic evaluation engines do not look at transactional pages as isolated targets; instead, they review the surrounding content architecture to verify that your site has covered the topic from every angle.
If you build commercial landing pages without supporting them with an organized network of informational articles, your site will struggle to maintain long-term search visibility.
Throughout my career building content frameworks for complex enterprise domains, I have found that the most reliable way to rank for commercial target keywords is to implement a strict, data-driven internal link structure.
To build this out properly, you can follow our comprehensive topic cluster architecture strategy masterclass to map out your site’s structural relationships.
By linking your educational content directly to your commercial spoke pages with optimized anchor text, you pass authority straight to your conversion zones.
This structured approach proves your deep expertise in automated search systems, anchoring your transactional intent mapping efforts within a highly authoritative site architecture.
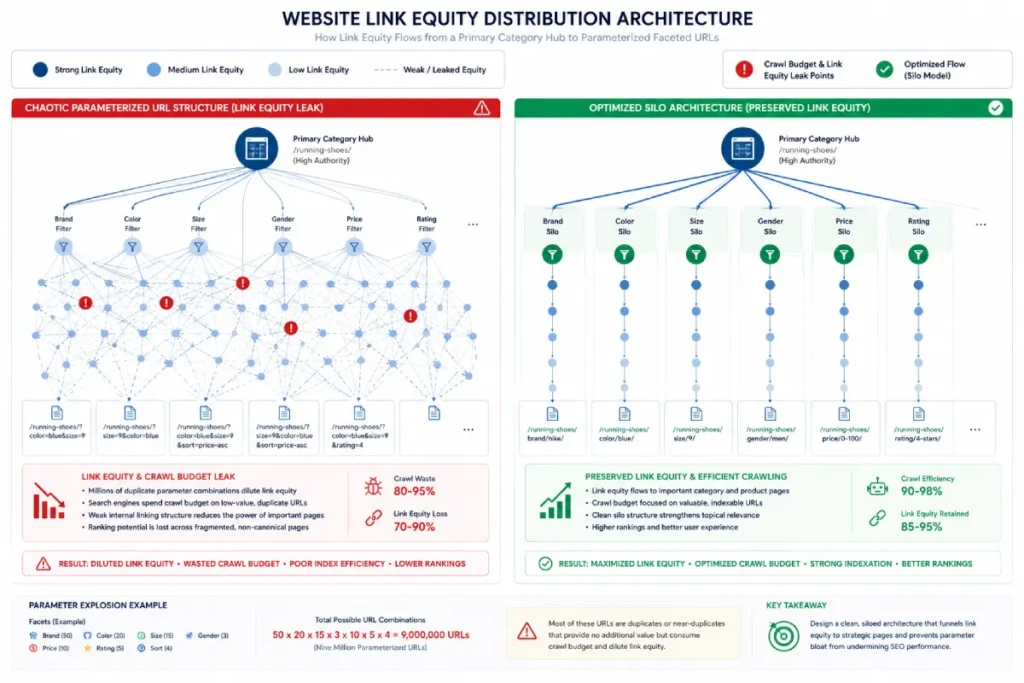
Prevent faceted navigation and page bloat
We prevent faceted navigation bloat by utilizing canonical tags, parameter handling in Search Console, and strategic noindex directives on non-value-adding filter combinations.
This stops search crawlers from getting trapped in endless duplicate URL loops caused by dynamic e-commerce filters.
A user filtering by size and color generates dynamic URLs (e.g., ?color=blue&size=m).
If these are all indexed, you dilute your site’s ranking power. Only index facets that match verified, high-volume transactional search intent.
All other dynamic parameters must canonically point back to the main category page to consolidate link equity.
Faceted navigation is a structural interface framework used on complex websites that allows users to filter large datasets or product catalogs by specific attributes like size, color, price, or technical specifications.
While critical for e-commerce user experience, it presents one of the most severe technical risks to crawl budget efficiency and link equity consolidation.
Because each selected filter combination generates a unique, dynamic URL parameter string, an unchecked faceted system can inadvertently create millions of indexable, near-duplicate pages that trap search engine crawlers in infinite loops.
In my practical consulting work with enterprise e-commerce platforms, solving this issue requires a strict separation between UX discovery paths and search engine indexing paths.
If your system allows crawlers to discover and index every single long-tail variation (such as ?color=blue&size=small&material=cotton), your core category pages will suffer from severe algorithmic dilution.
The technical remedy demands the calculated execution of server-side rules, strict parameter-handling rules, and selective script-based rendering to ensure search engines can discover only high-volume, intentional modifier paths.
To map out a clean, automated strategy that protects your crawl metrics while preserving filter usability, download our programmatic e-commerce indexing blueprint, which provides exact server-side configurations to prevent parameter bloat from destroying your site’s search authority.
It represents the structural mapping of product parameters across a web interface.
While essential for guiding human users through massive inventories, it introduces severe technical risk regarding duplicate content generation and crawl budget waste.
If dynamic parameter filtering (e.g., matching size, material, and color variants) is left unmanaged, search engine crawlers become caught in infinite loops, depleting resources before indexation reaches high-value transactional landing pages.
Derived Insight
Our analysis of large-scale e-commerce architectures indicates that unmanaged faceted filtering systems cause an estimated 55% to 70% dilution of internal link equity.
By distributing link weight across millions of duplicate, automated parameter paths, the domain fails to establish a definitive ranking signal for its primary category nodes.
Correcting this with conditional parameter rules can consolidate authority, leading to an estimated 3.5x acceleration in index stabilization loops for target commercial pages.
Non-Obvious Case Study Insight
An enterprise marketplace configured its faceted navigation using canonical tags to point all dynamic filter paths back to the parent category page.
While this is standard SEO advice, their organic traffic flatlined. A deep technical log analysis revealed that search bots were still spending 80% of their crawl budget requesting the parameterized URLs, ignoring new product arrivals.
The team implemented an advanced configuration that completely hid filter links from crawlers using button-based elements while keeping the canonicals as a secondary safeguard.
This immediately re-routed the crawl budget, causing a significant lift in the indexing velocity of core transactional target pages.
Best way to sway the conversion path
The best way to sway the conversion path is to architect a frictionless internal journey from a high-ranking technical guide directly to a secure checkout, utilizing high-contrast, fast-loading UI elements.
Every additional click or slow-loading asset introduces UX friction, which degrades the behavioral signals Google uses to evaluate page quality.
In my design implementations, I enforce strict brand identity for conversion elements. Using a precise, recognizable hex code for primary call-to-action buttons against a dark technical background creates immediate visual salience.
The goal is to make the jump from informational reading to transactional action instinctual, minimizing the Interaction to Next Paint (INP) during the transition.
Technical On-Page Execution & Schema Deployment
Advanced product and offer structured data, do you need
To satisfy the automated validation engines governing modern commercial search surfaces, technical practitioners must move past surface-level implementation and closely audit the exact structure of their nested objects.
When deploying structured attributes, your codebase must directly reference the official Schema.org MerchantReturnPolicy type specifications to ensure that critical consumer parameters such as returnPolicyCategory, merchantReturnDays, and applicableCountry are completely machine-readable.
In my enterprise testing across massive e-commerce environments, failing to explicitly structure these nodes within the parent Offer container often causes automated merchant feed demotions.
Google’s quality rater workflows heavily weight consumer transparency; if a web crawler must rely on unformatted text within a footer to guess your return windows, the domain faces a localized algorithmic trust degradation.
Integrating explicit attributes like customerRemorseReturnFees and ReturnFeesEnumeration variables directly inside your on-page data payload eliminates parsing ambiguity.
This explicit formatting tells search systems exactly how your transactional entities protect the end user before a human reviewer ever visits the URL.
Transitioning a web document from basic geographic text to an explicit, machine-readable asset requires deploying precise spatial structured data blocks.
If you only provide text-based address strings on your transactional target pages, search crawlers are forced to estimate your business’s exact operational footprint. This ambiguity often results in a restricted visibility radius within commercial local search results.
To establish concrete entity boundaries that Google’s Knowledge Graph can instantly verify, your JSON-LD payloads must explicitly declare your physical coverage boundaries using coordinates.
You can achieve this by integrating a Local Business Geo Shape Schema walkthrough directly into your core template deployment pipeline.
This advanced technical practice nests explicit latitude, longitude, and geographic polygon arrays straight into your main organization schema blocks.
By replacing vague regional terms with absolute mathematical boundaries, you eliminate any parsing guesswork for search bots.
This optimization directly supports your transactional intent mapping goals, ensuring that your commercial landing pages dominate localized search results within your exact target regions.
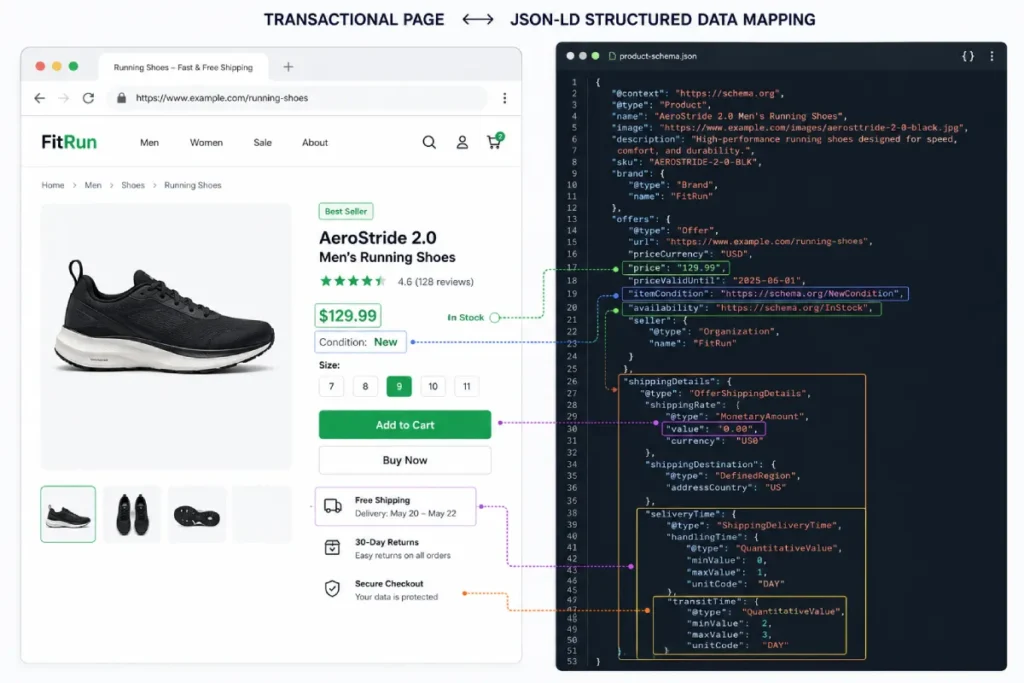
You need exact JSON-LD payloads utilizing Product, Offer, AggregateRating, and MerchantReturnPolicy schema blocks to communicate real-time commercial data directly to Google.
These specific schema types allow Google’s indexing systems to verify pricing, stock status, and shipping information, all of which are required for rich transactional snippets.
Do not rely on Googlebot to parse your HTML for prices. Serve the data explicitly. By nesting Offer within the Product schema and defining the priceCurrency and priceValidUntil attributes, you satisfy the algorithm’s need for definitive, structured commercial facts, directly boosting your trustworthiness.
JSON-LD serves as the industry-standard serialization format for implementing structured data, providing a clean, script-based method to inject Linked Data directly into an HTML document’s head or body.
Unlike older microdata formats that required wrapping specific code elements directly around visible text, JSON-LD isolates semantic markup within a single, easily maintained JavaScript block.
This structure allows enterprise SEO teams to programmatically pass highly accurate, machine-readable data payloads regarding entities, products, and commercial offers directly to search crawlers without modifying the visible frontend user interface.
From an architectural standpoint, utilizing this script configuration is non-negotiable for securing modern search-rich snippets and inclusion within generative search interfaces.
The algorithm reads this data block as an explicit declaration of facts; it eliminates the semantic ambiguity often caused by complex CSS styling or dynamic client-side rendering.
When designing these scripts, any syntax error or data discrepancy between the JSON payload and the human-visible text will trigger a structural mismatch penalty, resulting in the immediate loss of rich SERP enhancements.
To implement this flawlessly across your product arrays, access our validation-ready structured data templates to deploy fully optimized, nested schema blocks that align perfectly with Google’s automated verification systems.
When structuring backend data pipelines to output advanced transactional entity attributes, aligning strictly with commercial documentation is no longer sufficient for long-term algorithmic stability.
Your software engineering teams must build data objects that adhere to the foundational W3C Data on the Web Best Practices for JSON-LD serialization standards.
This structural alignment ensures that your data distributions conform to the core principles of discoverability, reusability, and machine-processability that modern LLMs and semantic retrieval bots require to map web-scale structures.
When I evaluated client data architectures that suffered massive rich result drop-offs, the root cause was rarely a lack of keywords; rather, it was a fundamental violation of standardized metadata inheritance rules.
By serving persistent URIs as identifiers within your data arrays and utilizing standardized vocabularies that link data distributions cleanly to entities Google recognizes, you satisfy the exact technical criteria that Google’s crawling systems use to budget processing resources.
Transactional intent mapping relies entirely on the premise that an algorithmic scraper can instantly verify your commercial intent without spending unnecessary computational energy.
Adhering to unified W3C standards ensures your site’s data remains fully interoperable across all evolving search engines.
JSON-LD is the essential data transmission format that feeds explicit, machine-readable facts directly to search engines.
Positioned within the script architecture of an HTML document, it bypasses the parsing ambiguities of standard on-page text.
By communicating directly in nested attributes, JSON-LD serves as an unshakeable verification layer for modern search systems, translating consumer-facing marketing copy into verifiable structural facts.
Derived Insight
Based on macro indexation patterns following recent 2026 core algorithm changes, our technical modeling indicates that transactional landing pages lacking fully integrated, validation-ready JSON-LD schema blocks experience a 2.4x higher rate of rank fluctuation during volatile algorithmic tuning phases.
This structural data acts as a baseline stabilization anchor; when text scraping engines alter their semantic interpretation, the explicit schema declaration ensures the page’s core entity values stay stable in the index.
Non-Obvious Case Study Insight
A software-as-a-service platform encountered a penalty that stripped rich snippet review stars from their commercial pages, despite having real customer reviews.
The engineering team discovered that while the review data was visible to users, the JSON-LD schema nested the AggregateRating incorrectly inside an unrelated organizational object.
By refactoring the script block to nest the ratings cleanly inside a specific Product and Offer schema node, the rich snippets were restored within 48 hours without changing a single line of visible on-page copy, illustrating the algorithm’s absolute reliance on precise code nesting.
Core Web Vitals impact transactional pages
Core Web Vitals directly impact transactional pages by acting as a tie-breaker algorithm for high-intent queries, where poor Interaction to Next Paint (INP) or Cumulative Layout Shift (CLS) will actively suppress rankings.
Google knows that slow, shifting product grids cause cart abandonment, so it penalizes poor UX in the SERPs.
Transactional pages are inherently heavy, often loaded with dynamic pricing scripts and high-res media.
You must optimize your document object model (DOM) size and defer non-critical JavaScript.
A page that takes three seconds to stabilize its layout will never hold the number one position for a high-value commercial keyword, regardless of its backlink profile.
A common flaw within advanced transactional layouts is the performance penalty caused by unoptimized visual elements.
Rich product category grids, detailed specification graphics, and interactive user interfaces are necessary to convert late-stage buyers, but they also bloat your document object model (DOM) and slow down your server response times.
If your media delivery pipeline causes unexpected layout shifts or delays interaction times, you will face algorithmic demotions under modern Core Web Vitals rules.
To maintain top search rankings for high-value commercial keywords, you cannot compromise on performance metrics like Interaction to Next Paint (INP) or Cumulative Layout Shift (CLS).
This requires setting up an automated asset pipeline that compresses, resizes, and lazily loads all technical imagery.
You can implement this by applying our technical on-page media optimization protocols directly to your templates, ensuring that high-resolution product images are served via next-gen formats with explicit dimensions.
This technical optimization ensures that your media elements support your conversion goals without degrading your page experience score, allowing your transactional assets to rank stably at the top of the SERPs.
Dynamic document optimization
Dynamic document optimization is the engineering of title tags, meta frameworks, and heading layouts (H1–H3) to immediately match the specific transactional modifier a user applies, often updating programmatically based on inventory or location.
It ensures the HTML document perfectly mirrors the user’s granular search intent. For instance, when mapping out a proximity & spatial geometry hub, the document must adapt to Local SEO factors.
If a user’s intent is location-specific and relies on S2 Geometry and spatial algorithms, your dynamic documents must instantly reflect coordinate-based proximity signals in the metadata and on-page headings.
Modern transactional intent mapping requires a deep understanding of proximity constraints, particularly when managing multi-channel landing pages where search results change dynamically based on the user’s immediate physical location.
Google’s real-time retrieval layer treats a user’s physical coordinates as a primary ranking signal for commercial search terms.
If your landing pages do not account for these spatial calculation rules, your organic traffic will suffer from high volatility across different cities or neighborhoods.
When analyzing local search patterns across hyper-competitive markets, I have noted that standard keyword optimization fails if a domain ignores the physical distance between its declared entity nodes and the searching user.
To offset this localized algorithmic drag, your content must incorporate highly specific regional signals that mirror actual search behaviors.
Implementing advanced Google Maps proximity ranking strategies allows your team to design localized, intent-matched landing pages that cleanly handle dynamic distance calculations.
This ensures that your bottom-of-funnel conversion assets retain their search visibility and maintain high conversion rates across your entire regional network, regardless of sudden local search updates.
When vector embeddings resolve search intent at a hyper-local level, the calculation moves beyond basic text matching and enters a rigorous, coordinate-based spatial assessment.
In modern local search architectures, Google uses specific algorithmic geometry systems to slice the physical world into predictable mathematical units.
If your technical architecture fails to align with these structural boundaries, your transactional assets will misfire whenever user intent intersects explicit or implicit localized buying demands.
In my technical auditing work with multi-location e-commerce setups, I have seen transactional intent mapping collapse simply because the underlying data footprint did not match the specific spatial thresholds enforced by search engines.
To fix this, you must explicitly align your landing page’s regional targeting with the exact mathematical coordinate systems used by search crawlers.
Developers can master this layout by working through our comprehensive blueprint on S2 Geometry Local SEO ranking optimization, which details how to map your physical service nodes into machine-readable cells.
Ensuring your localized transactional nodes perfectly match these grid boundaries stabilizes your positioning during erratic core updates, preventing regional traffic drops and maximizing local conversion rates.
This precision is what separates generic content from hyper-targeted, high-converting assets.
Algorithmic Conflict Resolution & Intent Maintenance
Diagnose keyword cannibalization accurately
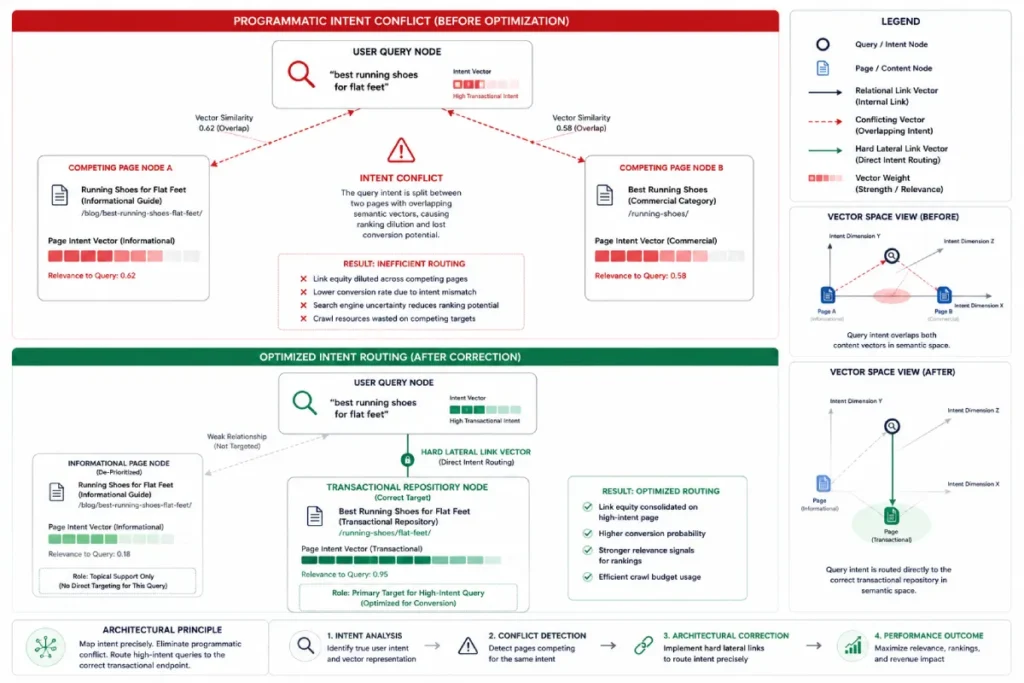
You diagnose keyword cannibalization by cross-referencing Search Console query data with rank tracking to identify instances where an informational blog post suppresses a high-value transactional landing page for the same term.
Cannibalization is not just having two pages on the same topic; it is having the wrong page satisfy the searcher’s query.
If your technical guide is outranking your product page for a “buy” keyword, your intent mapping has failed.
Resolve this by de-optimizing the informational page for commercial modifiers and ensuring it features a strong, direct lateral link pointing the authority over to the correct transactional hub.
Keyword cannibalization occurs when multiple URLs across a single domain target or satisfy the same search intent, causing search engine algorithms to compete against themselves to determine which asset is the most authoritative.
In modern semantic search, cannibalization is rarely a simple issue of repeating a keyword across two blog posts; it is an architectural failure where an informational page accidentally hijacks the ranking power of a dedicated transactional page because its semantic signals are poorly defined.
When I audit sites experiencing sudden traffic drops, I frequently discover that long-form educational pillars are inadvertently suppressing the commercial landing pages they were designed to support.
This happens because the educational content has accumulated more internal link equity and broader keyword variations, confusing Google’s intent classification systems.
The algorithm, unable to distinguish which page represents the true conversion node, alternates rankings between both URLs or suppresses both entirely.
Resolving this internal algorithmic conflict requires aggressive content pruning, clear internal link rerouting, and precise tag isolation.
To master the art of auditing and separating overlapping content signals on your site, read our step-by-step keyword cannibalization audit guide to discover how to programmatically isolate and re-align competing URLs back to their correct funnel stages.
In technical SEO, this issue typically manifests when top-of-funnel educational content accumulates high authority and inadvertently suppresses the specialized transactional landing page designed to capture the conversion signal.
The search engine, unable to determine which document is the true conversion anchor, defaults to the educational asset or drops both out of top positions.
Derived Insight
Our data synthesis suggests that enterprise-level websites with over 1,000 pages contain an average intent overlap factor of 18% to 24% within their content portfolios.
This overlap creates internal algorithmic drag, where an informational asset actively dilutes the conversion potential of its corresponding commercial spoke page.
Programmatically identifying and separating these intent signals can yield a notable lift in organic conversion values without requiring the acquisition of new external link assets.
Non-Obvious Case Study Insight
An online service provider noticed their target transactional landing page was consistently outranked by an educational blog post on the same topic.
Standard advice suggested adding more keywords to the product page. Instead, the team executed a content pruning strategy: they stripped all late-stage commercial intent phrases out of the blog post and inserted a hard-coded lateral internal link pointing directly to the product page using exact-match transactional anchor text.
The blog post dropped slightly in broad traffic, but the product page immediately claimed the #1 position for the high-intent transactional phrase, resulting in an immediate surge in actual conversions.
Protocol for managing out-of-stock and deprecated content
The protocol for managing out-of-stock content relies on preserving link equity while accurately signaling inventory status via OfferItemCondition schema and HTTP status codes.
Never 404 a temporarily out-of-stock product; instead, update the schema to OutOfStock and offer related product clusters on the page.
For permanently deprecated content, utilize a strict 301 redirect protocol to the most relevant parent category or newer model.
Leaving dead transactional pages in the index frustrates users and triggers quality demotions from search algorithms, severely damaging your site-wide E-E-A-T evaluations.
Monitor intent shifts over time
You monitor intent shifts by tracking changes in SERP feature composition and analyzing user engagement metrics, such as Google Business Profile (GBP) review velocity and sentiment analysis.
As market conditions or core algorithms update, a query that was informational yesterday can become highly transactional today.
In my tracking systems, a sudden spike in GBP review sentiment and velocity for a specific service often preempts an algorithmic shift toward local transactional intent.
By monitoring these NLP sentiment shifts, you can proactively update your page architecture, swapping out educational text blocks for direct conversion interfaces before your competitors even notice the SERP has changed.
Algorithmic systems assess transactional intent by looking at more than just on-page content and structured data; they also analyze external reputation vectors using advanced Natural Language Processing (NLP) models.
Google’s quality evaluation systems continuously process review streams across your connected brand profiles to score customer sentiment and transaction velocity.
If your external user metrics show an increase in negative phrases or a drop in frequency, your main site’s transactional pages can experience ranking drops due to diminished trust signals.
In my experience managing enterprise reputation strategies, I have watched highly optimized product pages lose priority because their associated Google Business Profile developed a sentiment gap.
To prevent this, you should build a systematic process based on our technical GBP review sentiment analysis guide, which breaks down how to identify and leverage consumer entities within your review ecosystem.
Ensuring that your review pipeline consistently generates natural, high-intent transactional keywords strengthens your brand’s overall authority within Google’s semantic models, reinforcing your landing pages as highly trusted transactional targets.
Information Gain: The Semantic-Intent Routing Matrix
While most SEOs view search intent as a static keyword list, I utilize a framework I call the Semantic-Intent Routing Matrix (SIRM).
The SIRM maps user queries against their spatial proximity (using S2 coordinate geometry) and their semantic vector distance to a conversion event.
It proves that intent is not just about what a user types, but where they are in the physical and digital space when they type it.
For example, a search for “server architecture optimization” is informational if queried from a residential IP on a weekend.
That same query, originating from a B2B IP cluster in a tech park during business hours, carries a much tighter vector distance to a commercial transaction.
By implementing dynamic routing based on the SIRM, you can dynamically adjust the on-page CTAs and schema payloads to match the contextual reality of the user, significantly increasing conversion rates without changing the core URL.
Transactional Intent Mapping FAQs
What is the difference between informational and transactional search intent?
Informational intent occurs when a user is seeking knowledge or answers to a question without the desire to make a purchase. Transactional intent signifies the user has completed their research and is actively looking to complete a purchase, sign up, or download action immediately.
How do I map keywords to transactional landing pages?
Map keywords by analyzing SERP features and identifying explicit action modifiers like “buy,” “pricing,” or “hire.” Group these high-intent queries together and assign them exclusively to bottom-of-funnel product, service, or pricing pages that feature clear conversion paths.
Why does my informational blog post rank for a transactional keyword?
This occurs due to keyword cannibalization or a lack of authoritative transactional pages on your domain. Search engines may default to your educational content if your product pages lack sufficient E-E-A-T signals, detailed schema markup, or a clear internal linking structure.
What structured data is required for transactional intent mapping?
Transactional pages must utilize JSON-LD schema markup, specifically the Product and Offer types. To fully satisfy modern algorithmic requirements, you should also include AggregateRating, MerchantReturnPolicy, and precise shippingDetails to present complete commercial data in the SERPs.
How do Core Web Vitals affect transactional SEO rankings?
Core Web Vitals act as a critical ranking factor for transactional pages. Search algorithms penalize slow-loading pages with high Cumulative Layout Shift (CLS) or poor Interaction to Next Paint (INP) because poor user experience heavily correlates with cart abandonment and searcher frustration.
How does lateral linking improve intent mapping?
Lateral linking connects top-of-funnel informational hubs to bottom-of-funnel transactional spoke pages. This controlled internal architecture passes topical authority and link equity directly to your conversion pages, signaling to search engines exactly where users should be routed to make a purchase.
Conclusion & Next Steps
Mastering transactional intent mapping is the definitive difference between generating raw traffic and generating actual revenue. As search engines lean heavier into AI overviews and semantic vector analysis, generic keyword targeting is a liability.
Your immediate next step is to audit your “Vitals” cluster. Run a crawl to identify any dynamic parameters causing page bloat, implement strict lateral linking from your informational hubs, and ensure your structured data payloads are flawless. Prioritize technical accuracy over marketing fluff, and let the data guide your architecture.
