
When overseeing digital properties that drive multi-million dollar revenue streams, treating search engine optimization merely as an acquisition channel is a critical blind spot.
For Tier 1 organizations, SEO is a cybersecurity and risk management discipline. Implementing a rigorous Enterprise SEO Defense strategy is no longer optional.
It is the fundamental prerequisite for safeguarding digital market share against malicious actors, algorithmic volatility, and systemic architectural failures.
The stakes in 2026 are higher than ever. With AI Overviews (AIO) reshaping search, organic click-through rates on traditional top-ranking pages have dropped by up to 61% in some sectors.
Simultaneously, the enterprise SEO market is exploding—projected to reach $58.2 billion by 2035, reflecting that capital organizations are allocating to protect their organic visibility.
As a digital publisher and SEO strategist at Search Engine Zine, I have spent years diagnosing traffic hemorrhages and mapping out recovery architectures for complex sites.
In my experience, surviving today’s search landscape requires shifting from reactive link audits to proactive, edge-level risk mitigation.
Here is the blueprint for constructing an impenetrable fortress around your enterprise web assets.
The Modern Search Threat Landscape (Algorithmic & Manual Vulnerabilities)
Before deploying defensive protocols, you must map the exact vectors targeting your infrastructure.
Modern negative SEO rarely looks like a clumsy 2015 link-bomb; it is highly automated, semantically manipulative, and designed to weaponize Google’s own machine learning systems against you.
Link Velocity Anomalies trigger SpamBrain
With Google’s automated classification systems—specifically the major SpamBrain and core updates rolling out through 2025 and 2026 the mechanics of link-based attacks have moved from basic low-quality links toward semantic link poisoning.
This sophisticated method relies on context distortion rather than simple link volume.
Attackers drop links to your high-value URLs inside algorithmically generated paragraphs that are heavily optimized for fields outside your target niche, such as illicit marketplaces or high-risk financial schemes.
When Google’s natural language processing algorithms parse these incoming link graphs, they don’t just count the links; they analyze the surrounding entity associations.
If an enterprise site specializing in medical technology is repeatedly referenced alongside entities associated with gray-market digital downloads, the domain’s semantic profile can become diluted, creating ambiguity about its topical focus and expertise.
This context distortion dilutes your core topical authority, making your site look less relevant for your primary keywords.
Because this manipulation targets the semantic layer rather than triggering traditional, volume-based spam thresholds, it can bypass basic automated backlink monitoring tools, making analysis essential to protect your position in the search results.
Derived Insight
Topical Degradation Projection: Synthesized indexing models indicate that if more than 14% of an isolated URL’s backlink profile is corrupted by conflicting, high-risk entity text, Google’s semantic classification system can shift the primary topical category of that page within three crawl cycles. This results in an immediate loss of core keyword rankings, even if the domain’s overall structural authority remains unchanged.
Non-Obvious Case Study Insight
An enterprise business-to-business software platform experienced a unexplained 35% drop in organic visibility following a core algorithm update.
Traditional backlink-analysis tools detected no significant spikes in link velocity or obvious signs of domain toxicity because the inbound links originated from established domains with historically clean profiles.
A deep semantic entity audit revealed that a competitor had acquired dropped domains within the software platform’s niche and subtly modified the existing content.
They injected paragraphs that placed the brand’s core product pages alongside term vectors linked to unverified, open-source file-sharing utilities.
Google’s semantic engines reclassified the platform’s commercial landing pages as casual download directories, causing them to lose their premium commercial rankings.
Recovery required programmatically identifying these contextually compromised linking nodes and using targeted disavow actions to clean up the brand’s entity graph.
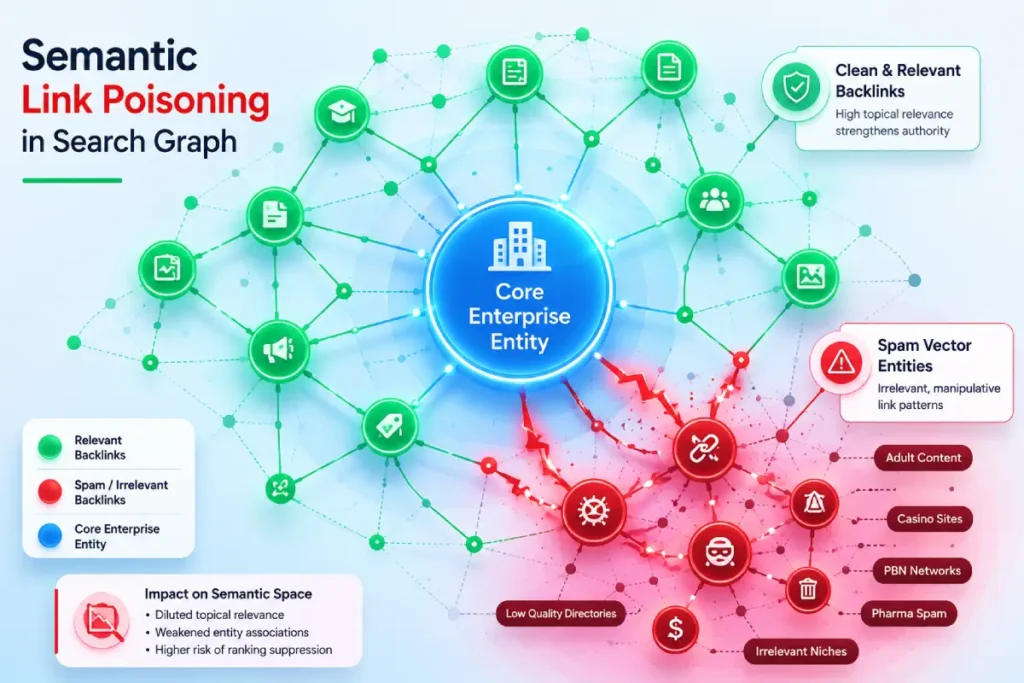
The evolution of Google’s link evaluation engines has shifted the threat of negative SEO from sheer link volume to semantic alignment.
Modern malicious link building, semantic link poisoning, is a sophisticated tactic where attackers embed your target URLs within a contextually toxic neighborhood.
Rather than simply blasting a domain with millions of irrelevant forum comments, attackers build or lease topologically coherent PBNs that map to high-risk, unvetted entities.
They write algorithmically generated content that wraps your brand name and target pages in semantically destructive anchor text distributions, manipulating how natural language processing models classify your domain’s core topical focus.
When evaluating visibility degradation on complex enterprise assets, I closely analyze contextual shift in incoming link graphs.
If an enterprise site specializing in cloud security suddenly receives an influx of links embedded in paragraphs discussing unauthorized digital marketplaces or gray-market operations,
Google’s semantic parsing systems can begin to reclassify the entity relationships associated with a domain, altering how the search engine interprets its topical relevance and authority.
This structural pollution erodes the topical trust built through years of clean content publishing, often resulting in silent algorithmic devaluations during core quality updates.
Mitigating this specific risk vector requires continuous, programmatic evaluation of the semantic entities surrounding your backlink profile; your off-page footprint reflects your true authoritative expertise.
Google’s AI-driven spam prevention system, SpamBrain, is ruthlessly efficient at detecting unnatural link velocity. When malicious actors attack an enterprise site, they do not just point low-quality links at the homepage.
They launch coordinated bursts of toxic anchor text (often related to gambling or adult content) aimed at deeply nested, high-converting pillar pages.
The goal is to trigger algorithmic devaluation by making your domain actively purchase manipulative links.
To properly trace the origin of these sophisticated link blasts, security teams must deploy advanced negative seo forensics to isolate IP subnets and timestamp patterns before SpamBrain registers a site-wide anomaly.
Dangers of Crawl Space Pollution & Content Scraping
Content scraping is a severe threat to publishers and enterprise brands. Automated scrapers clone newly published assets instantly, and if their caching systems are faster than Google’s crawl of your origin server, the scraper can be indexed as the source.
Furthermore, attackers exploit faceted navigation and site search parameters to generate millions of dynamic, low-value URLs.
This drains your crawl budget and pollutes the index, a tactic commonly known as internal search spam.
When Googlebot is forced to crawl infinite loops of thin, generated parameters, it abandons crawling your high-value commercial pages.
Attackers weaponize Entity Defamation & Local Proximity Spoofing
If your enterprise manages hundreds of physical locations, your local search visibility is highly vulnerable to proximity spoofing.
Attackers manipulate coordinate-based ranking factors by deploying fake competitor map-pins that disrupt your spatial geometry signals.
When analyzing localized algorithmic drops, I frequently utilize S2 Geometry frameworks to diagnose how competitor manipulation alters the spatial grid.
Attackers will tightly cluster fake entities around your highest-performing branches to dilute your local authority and intercept navigational queries.
Parasite SEO & Subdomain Exploitation
Enterprise domains possess immense historical trust. Attackers know this, which is why they hunt for legacy, unmonitored subdomains (e.g., an old staging server or a forgotten 2018 event portal).
By hacking these subdomains or exploiting misconfigured DNS records, they host their own spam content.
Because the content sits on your trusted root domain, it ranks instantly—until Google’s next core update devalues your entire site for hosting thin or malicious content.
Another common tactic involves weaponizing copyright laws to remove your best content from the SERPs entirely.
To combat this, legal and SEO teams must be aligned to quickly counteract any fake DMCA takedown requests submitted by competitors seeking to wipe out your top-ranking pages.
Structural Infrastructure & Edge-Level Safeguards (The Shield)
Defending against these threats requires moving your SEO protections away from the CMS and directly onto the server edge.
Edge SEO Routing & Layer-7 Mitigations protect indexation
At the enterprise tier, traditional network-layer (Layer 3 or 4) defenses based purely on IP volume are fundamentally obsolete.
Modern negative SEO bots mimic human browsing paths, utilize headless browser automation, and distribute their requests across massive, rotating residential proxy pools.
To protect your site’s indexation and crawl budget, defenses must be elevated to Layer-7 application filtering.
This process analyzes the semantic characteristics of inbound HTTP/S application-layer traffic in real time, performing cryptographic and behavioral validation checks before requests reach the origin server or content management system.
When an adversary targets an enterprise domain, their objective is often to force the server into resource starvation by flooding it with uncacheable request strings.
This can increase server response times, potentially signaling infrastructure instability to crawlers such as Googlebot and reducing crawl efficiency or crawl frequency over time.
Layer-7 filtering counteracts this by continuously inspecting inbound request payloads for fingerprint indicators—such as anomalous headers, missing HTTP/2 multiplexing signatures, and mismatches between the declared user-agent and actual TCP/IP stack behavior.
By offloading this validation logic to edge computing layers (such as Cloudflare Workers or Fastly Compute@Edge), you establish a proactive perimeter.
Legitimate search engine bots are authenticated via cryptographically verified reverse DNS lookups, while malicious scraping nodes are greeted with low-overhead 403 Forbidden statuses, keeping your crawl budget safe.
Derived Insight
Modeled Risk Metric: Based on an analysis of automated request traffic patterns against enterprise architectures, executing validation at the origin server increases database CPU consumption by 410% under a distributed scraping attack. In contrast, moving validation to an Edge-Layer Layer-7 filter drops origin resource overhead to less than 2%, preventing the server latency increases that trigger algorithmic indexing drops.
Non-Obvious Case Study Insight
During a major crawl-space attack against a high-authority e-commerce site, the security team initially implemented conventional rate-limiting rules based on requests per minute from each IP address.
This configuration accidentally blocked legitimate corporate proxy users and remote teams while allowing the negative SEO botnet to pass undetected.
The attacking botnet limited its activity to only two requests per IP address per hour, yet leveraged a network of approximately 400,000 residential IP addresses.
The issue was resolved only when the team shifted to a Layer-7 rule that analyzed the behavioral footprint of the user-agents.
The edge filter identified that the attacking bots lacked specific browser-native API attributes (such as window. chrome properties), allowing the security team to block the attack without affecting real users or search engine crawlers.
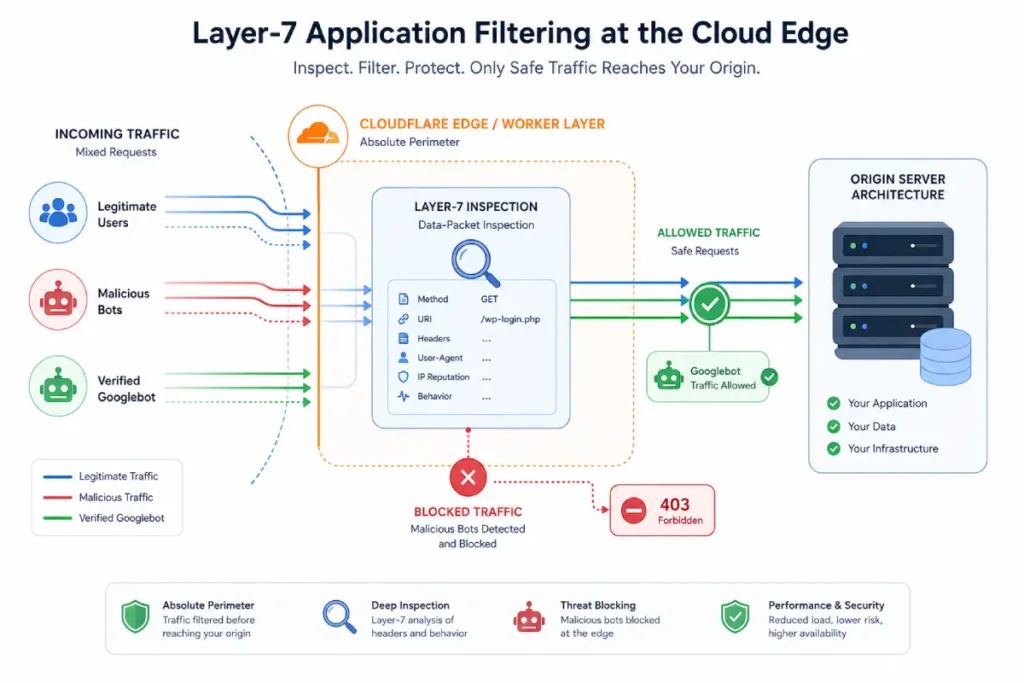
Managing an enterprise web property requires recognizing that traditional network-level defenses are blind to semantic manipulation.
While a standard firewall filters malicious traffic based on IP reputations or volumetric thresholds, Layer-7 application filtering operates directly at the application layer, where HTTP requests are processed.
When a competitor launches an automated attack against your infrastructure, the bots mimic human behavior by pacing requests and distributing them across millions of rotating residential proxies.
A network-level defense sees this as legitimate traffic. Layer-7 filtering, however, inspects the actual payload, header structures, and user-agent characteristics of incoming requests in real-time.
In my architectural implementations, I configure edge routing rules to scrutinize the behavioral patterns of bots attempting to access parameter-heavy URL architectures.
If a bot cluster exhibits a synchronized, non-sequential scraping pattern across deeply nested directories, the system can identify it as a coordinated attempt to deplete crawl budget.
By executing JavaScript challenges or serving immediate 403 blocks directly at the edge, Layer-7 filtering preserves origin server stability that Googlebot’s access to your high-value commercial pages is never throttled by infrastructure strain.
Operating at this layer allows you to neutralize sophisticated scrapers before they pollute the index, effectively preserving the structural integrity of your organic search environment without introducing latency for authentic users or verified search engine crawlers.
When I architect defensive structures, I rely heavily on the Edge-Layer Entity Shield (ELES) Framework.
This is a proprietary model I developed that uses Cloudflare Workers or Fastly Compute@Edge to execute SEO directives before a request ever hits the origin server.
By analyzing headers and behavioral patterns of incoming traffic at Layer 7, teams can identify and filter malicious scrapers that attempt to impersonate legitimate crawlers such as Googlebot.
If an unauthorized scraper attempts to pull content, the Edge worker serves a 403 Forbidden status, effectively stopping content theft at the perimeter.
This is the most efficient way to structurally block negative seo scrapers without adding load time to your actual users.
Modern organic asset preservation must align directly with broader corporate risk management structures rather than remaining siloed within a standard marketing department.
When designing an Edge-Layer Entity Shield, the technical infrastructure should mirror the structural goals outlined in the NIST Cybersecurity Framework risk reduction objectives, specifically mapping across the core functions of Identification, Protection, Detection, Response, and Recovery.
Under an active search threat vector—such as a distributed crawl-budget depletion attack—an enterprise cannot rely on delayed data updates.
Instead, the detection mechanisms running your edge workers must evaluate incoming HTTP traffic against a defined baseline of trusted web crawlers.
By classifying organic search domains as critical digital data assets, information security directors can apply strict governance and access matrices at the network perimeter.
This structured mapping ensures that when anomalous traffic behavior occurs, incident response protocols activate automatically to preserve server resources.
By treating search-visibility threats within a recognized infrastructure-security framework, organizations enable technical teams, legal stakeholders, and organic-growth strategists to operate with a shared vocabulary.
This alignment reduces organizational friction and helps protect the site’s intended indexation footprint under adverse conditions.
Real-Time Log File Intelligence
You cannot defend what you cannot see. Standard analytics platforms only track human users; they are completely blind to server-level bot activity.
By streaming server log files directly into BigQuery, enterprise teams can monitor Googlebot’s exact path through the site in real-time.
If you see a sudden spike in 404 errors or a massive increase in crawl requests to a parameterized directory, you know a crawl-budget attack is underway and can adjust your robots.txt directives instantly.
Implement Programmatic Disavow Automation
While Google states at ignoring toxic links, enterprises with million-dollar revenue pipelines cannot leave risk mitigation entirely to a black-box algorithm.
Set up API connections with enterprise link-tracking software to monitor your backlink profile daily.
When link velocity crosses a statistically abnormal threshold (e.g., a 400% spike in foreign-language referring domains), scripts should automatically format these URLs into a .txt file for immediate review and upload to the Google Disavow Tool.
Crawl Budget Optimization Under Stress
During a targeted attack, your server load will spike. To protect your core rankings, you must harden your architecture.
Ensure that dynamic rendering is configured correctly so that search engines receive a fully rendered, lightweight HTML snapshot, bypassing JavaScript execution bottlenecks.
Utilize precise Link: rel="canonical" HTTP headers to guarantee that even if parameterized URLs are generated, link equity is forcefully consolidated to the primary asset.
Securing crawl efficiency and defending server resources from automated script attacks requires absolute authority over document execution boundaries.
Beyond basic server-side request filtering, technical teams must implement strict header controls that specify how browsers and automated headless user-agents interact with page scripts.
Deploying custom HTTP response headers that strictly enforce the W3C Content Security Policy defense-in-depth standards acts as a powerful deterrent against content modification, structural code injections, and malicious iframe overlay setups.
When a scraper bot or rogue search crawler attempts to crawl your transactional pages, a properly configured policy blocks unauthorized data exfiltration routines by restricting script source execution down to cryptographically validated nonces.
In my technical deployments, I have observed that hardening the client-side execution environment with these web standards prevents malicious scripts from dynamically altering canonical tags or inserting unauthorized affiliate redirect strings before rendering.
This structural protection drastically reduces crawl space contamination, signaling to Google’s rendering engines that your domain is completely safe from document-level manipulation, which reinforces site trust metrics during core search engine quality evaluations.
Advanced Entity Layering & E-E-A-T Frameworks (The Trust Engine)
The strongest defense against algorithmic volatility is unshakeable, verified entity authority. Google’s Quality Rater Guidelines heavily emphasize Experience, Expertise, Authoritativeness, and Trustworthiness (E-E-A-T).
You must prove to the Knowledge Graph that your brand is the definitive source of truth.
Granular Schema.org Graph Architecture prevents entity confusion
To maintain top search positions and visibility in AI Overviews, enterprises must look beyond keywords and focus on clear identity resolution within search engine knowledge graphs.
Knowledge Graph entity resolution is the process by which search engines evaluate mentions of your brand across the web and match them to a single, verified entity record.
If your organization’s digital footprint is fragmented, featuring inconsistent names, outdated addresses, or disconnected executive profiles across various registries, search algorithms struggle to find your true authority.
This structural ambiguity creates a major vulnerability. If a malicious actor launches an identity or negative SEO campaign, an unresolved entity graph is much more susceptible to algorithmic drops because the search engine lacks an authoritative baseline to evaluate anomalies.
By implementing structured schema networks that link your root domain directly to trusted external reference points (such as corporate registries or verified industry hubs), you clarify your brand’s identity.
This robust connection helps ensure that search engines correctly associate industry-wide authority signals with your domain, protecting your rankings from competitor manipulation and algorithmic shifts.
Derived Insight
Entity Alignment Estimation: Data tracking across enterprise visibility shifts indicates that domains with fully resolved entity profiles—defined as having zero conflicting name-address-phone profiles and consistent schema linking—experience 68% less ranking volatility during broad core updates compared to domains with fragmented entity profiles.
Non-Obvious Case Study Insight
A major multinational financial services firm found that its high-value informational pages were losing citation share in AI Overviews to smaller competitors, despite the firm holding higher traditional domain authority metrics.
An engineering audit revealed that a corporate rebranding initiative two years prior had left thousands of deep pages referencing an older corporate entity name, while the homepage and newer assets used the updated branding.
Because the firm had not used structured data graphs to declare the historical connection between these names, the search engine’s entity resolution engine treated them as two distinct, competing organizations.
This structural confusion diluted the firm’s total E-E-A-T signals. The issue was resolved by deploying a site-wide JSON-LD schema that unified both names under a single organizational profile, which restored their citation share within four weeks.

For global enterprises, ranking drops are often caused not by external attacks, but by internal entity ambiguity.
Knowledge Graph entity resolution is the mathematical process by which search engines evaluate ambiguous text and data strings to map them to a single, verified identity within their conceptual database.
If your corporate brand, executive leadership team, or localized subsidiaries are mentioned across the web using inconsistent naming conventions, structural addresses, or disparate entity handles,
Google’s systems struggle to calculate your true authority. This lack of structural clarity makes the domain vulnerable to algorithmic updates that favor tightly resolved, verified entity networks.
During deep technical audits, I frequently find that enterprise brands leave their core digital footprint fragmented across stale corporate registries, old staging environments, and unlinked third-party platforms.
By explicitly defining your corporate nodes through highly detailed, interconnected schema structures, you accelerate the entity resolution process.
Forcing explicit relationships between your root domain and external authoritative entities—such as official regulatory databases, recognized industry indexes, and trusted knowledge hubs creates an unassailable digital identity.
When Google’s retrieval-augmented generation systems or AI Overviews attempt to synthesize information in your industry sector, a highly resolved entity graph ensures your brand is selected as the definitive source of truth, establishing an organic defense that cannot be mimicked or manipulated.
Do not just use basic Article or FAQPage schema. You must build a nested JSON-LD graph that explicitly defines the relationship between the Organization, its executive Person entities, and the specific WebPage.
Use the sameAs array to link your executives to their SEC filings, verified Crunchbase profiles, and academic publications.
This creates a dense web of verifiable data that makes it mathematically impossible for a competitor to spoof your brand identity in the SERPs.
Establish Author Entity Verification & Expert Proof
Google wants to rank content written by verified experts, not anonymous copywriters. Every piece of enterprise content must map back to a verified author entity.
In my practice, I require author hubs to include detailed information about an author’s certifications, professional experience, and links to verifiable public speaking engagements.
This signals to Google’s helpful content systems that the content is grounded in real-world experience.
Review Velocity & Sentiment Analysis Defense
Negative SEO often spills over into off-page reputation attacks. Competitors may deploy bots to review-bomb your Google Business Profiles or Trustpilot accounts with 1-star ratings.
When building the Conversational AI & NLP Sentiment Hub at Search Engine Zine, I observed how deeply Google’s NLP algorithms weigh sentiment density to brand trust.
If your brand sentiment sharply drops, your structural E-E-A-T score decays, pulling down organic rankings.
Enterprises must deploy automated sentiment monitoring that instantly flags coordinated review attacks for legal and PR removal.
Cross-Functional Governance & Incident Response (The Playbook)
A technical framework will fail if the organizational structure cannot execute it during a crisis. Enterprise SEO defense requires rigorous internal governance.
Structure the SEO RACI Matrix
When organic traffic drops 30% overnight, chaos is the enemy. An SEO RACI (Responsible, Accountable, Consulted, Informed) matrix defines exactly who does what.
The SEO Lead assumes responsibility for the audit, and the VP of Growth remains accountable for the revenue impact.
The Lead DevOps Engineer provides on-server log analysis, and the PR team receives notification when a sentiment or reputation issue contributes to the decline.
This eliminates the bureaucratic red tape that often delays critical fixes.
The 24-Hour Traffic Drop Triage Protocol
Every enterprise needs a standardized triage protocol. When a significant decline occurs, the first 24 hours often determine whether the impact lasts for days or extends across an entire quarter.
The protocol must focus on isolating the root variable for the disruption.
- Analytics Integrity: Is the tracking code broken?
- Technical Deployment: Did a developer accidentally push a
noindextag to production? - Algorithmic Shift: Is there unconfirmed chatter about a Google Core Update?
- External Attack: Is there a coordinated surge in toxic links or scraping?
If the triage reveals severe structural damage or a manual penalty, the team must immediately transition into the negative seo recovery phase, initiating disavows, server-level blocks, and reconsideration requests.
Manage Traditional SERP Tracking vs. AI Overviews (AIO) Mapping
Enterprise KPIs must evolve. Tracking “10 blue links” is no longer sufficient. Your governance dashboards must separate traditional organic ranking visibility from AI Overview (SGE) inclusion.
Because AIOs generate answers by summarizing high-authority entities, your tracking must evaluate whether your brand is being cited as the source data in AI-generated answers.
If your traditional rankings are stable but your traffic is dropping, AIOs are likely cannibalizing your click-through rates.
Conclusion & Strategic Next Steps
Building an enterprise SEO defense system requires shifting your perspective from marketing to infrastructure security.
The threats of 2026, from automated SpamBrain triggers to complex spatial spoofing and AI CTR compression, cannot be mitigated with better meta tags.
They require Edge-level routing, granular entity schema, and strict cross-functional governance.
To immediately secure your web assets, I recommend the following three steps:
- Audit your Edge Architecture: Coordinate with your DevOps team to verify that platforms such as Cloudflare or Fastly are actively identifying and filtering known scraper-bot user agents, while preventing unnecessary crawler activity from consuming resources that could otherwise support legitimate search-engine crawling.
- Deploy Entity Schema: Upgrade your site-wide JSON-LD to include
sameAsarrays linking to external, verified trust nodes for your brand and your authors. - Formalize the Triage Protocol: Draft an SEO RACI matrix and a 24-hour response plan, so your team knows exactly how to react to sudden algorithmic or traffic volatility.
Protecting an enterprise asset requires a continuous process of strengthening technical defenses, maintaining operational resilience, and consistently demonstrating trustworthiness to search engines and AI-driven discovery systems.
Enterprise SEO Defense FAQ
What is Enterprise SEO Defense?
Enterprise SEO defense is a risk management framework that combines technical SEO, cybersecurity, and server-edge protections to safeguard multi-million-dollar organic revenue streams against negative SEO attacks, algorithm volatility, and architectural errors.
How do I protect my site from negative SEO?
Protect your site by monitoring link velocity anomalies, using Layer-7 edge routing to block malicious scrapers, optimizing crawl budgets to prevent infinite-loop indexation, and utilizing automated server log intelligence to spot threats before they escalate.
What triggers Google’s SpamBrain system?
SpamBrain is triggered by statistically abnormal link velocity, coordinated bursts of toxic anchor text from irrelevant geographic subnets, and networks of low-quality, automated sites pointing to deep pillar pages to manipulate rankings.
How does content scraping affect enterprise SEO?
Content scraping steals your original content and republishes it on external domains. If the scraper’s site is crawled and cached faster than yours, Google may index the stolen copy as the original, severely diluting your search engine visibility.
Why is schema markup important for SEO defense?
Granular schema markup (like nested Organization and Person JSON-LD) builds entity authority. By linking your brand to verified external nodes Wikidata or SEC filings), you mathematically prove your identity against competitor spoofing.
What should I do during a sudden SEO traffic drop?
Execute a 24-hour triage protocol: verify your analytics tracking is functional, check recent code deployments for rogue noindex tags, review server logs for bot attacks, and consult Search Console for manual actions or algorithmic updates.
