
- 01 The Ontology of a Knowledge Graph Node
- 02 The Mechanics of Node Attachment
- 03 Node Reconciliation: Entity Mergers
- 04 The Role of Schema in Node Propagation
- 05 Original Insight: The “NEW” Model
- 06 Detecting Node Drift and Decay
- 07 Practical Next Steps for Your Business
- 08 Conclusion
- 09 Knowledge Graph Node FAQ
In the modern search landscape, text-matching algorithms have taken a back seat to a highly sophisticated system built on entities, attributes, and relationships.
To understand how your business is surfaced in search results or summarized in AI Overviews, you must move away from strings of text and look at the underlying data layer: the knowledge graph node.
A knowledge graph node is the singular digital anchor that represents a distinct entity—such as a person, place, or business organization—within a search engine’s semantic database.
When Google crawls the open web, its primary goal is not just indexing pages, but extracting facts to anchor to these nodes.
According to data from the global knowledge graph market, the enterprise data segment is experiencing a massive compound annual growth rate of over 31%, driven by the absolute necessity of grounding generative AI and large language models (LLMs) in structured, verifiable facts.
Google’s own public data confirms that its Knowledge Graph contains over 500 billion facts mapping to roughly 5 billion unique entities.
For digital publishers and SEO strategists, this is the architectural playground that determines your brand’s visibility.
If your website or local profile loses its visibility without any technical errors present on the site, you are likely suffering from a structural disconnection from your primary entity node.
In my experience executing recovery campaigns for multi-location brands, fixing a ranking drop is rarely a matter of building more content; it requires diagnosing and resolving conflicts within the entity node pipeline.
The Ontology of a Knowledge Graph Node
To engineer your web presence for maximum entity authority, you must understand how a search engine translates your raw text into machine-readable network graphs.
Search engines parse business entities.
Entity disambiguation is the mathematical sorting algorithm Google deploys to distinguish between distinct entities that share highly similar textual markers, such as matching brand names or overlapping geographic service boundaries.
In a dense marketplace environment, names alone are highly insufficient identifiers; the system must process hundreds of secondary signals to confirm whether an independent web asset belongs to an existing or entirely new node in the graph.
When this system encounters unstructured citations that look identical, it experiences high logical friction.
If the internal resolution thresholds are not met, the engine will often suppress both profiles or mistakenly cluster them into a single, corrupted profile, which triggers catastrophic local ranking loss.
Entity disambiguation is the definitive battlefield for local and enterprise brands. When multiple businesses operate under highly similar brand names, offer identical services, or share commercial office spaces within a dense urban environment.
Google’s ranking systems must apply probabilistic models to ensure they do not serve an incorrect result.
If the algorithm lacks sufficient mathematical confidence to distinguish your specific business from another nearby entity, it triggers an unannounced filtering protocol.
This protocol intentionally limits your organic reach to mitigate user confusion. Most SEOs misdiagnose this issue as a content problem or a lack of backlinks, but it is actually a fundamental failure of entity separation.
The evolution of conversational interfaces and semantic search systems has fundamentally altered how long-tail search intent is parsed and answered.
Modern search engines do not treat highly specific, multi-word search queries as separate strings requiring individual keyword pages; instead, they map these variations as contextual extensions of an established root entity.
In my field consulting, I find that brands attempting to scale visibility by spinning out near-duplicate pages for every long-tail keyword variant inadvertently trigger internal cannibalization filters.
Advanced visibility optimization requires building a single, highly authoritative root node that possesses the semantic capacity to answer hyper-specific, intent-driven queries naturally.
Building an unshakeable semantic network requires a deep structural understanding of the Schema.org data dictionary type hierarchy.
Every single property nested within your entity block must strictly inherit its definitions from this open-source vocabulary.
If you populate non-standard fields or use improper data types within your schema code, you create structural syntax noise that can cause search engine crawlers to reject the entire block.
For instance, when mapping localized operations, you should always choose the most specific available subtype of Organization or LocalBusiness rather than using generic, high-level classifications.
This technical precision ensures your digital footprint is cleanly ingested by natural language processing models, laying a solid foundation for your long-tail search visibility.
By auditing your code against this master vocabulary, you guarantee that every subject-predicate-object triple generated by your site is formatted with maximum algorithmic clarity.
To satisfy the modern requirements of Information Gain, your primary content assets must be built to answer deep user questions through natural language patterns.
When your writing style focuses on clear subject-predicate-object triples, you allow automated parsers to match your content directly with long-tail conversational searches.
Implementing a rigorous framework based on the science of semantic long tail discovery allows you to capture highly conversion-ready traffic without relying on old-school keyword stuffing techniques.
This precise mapping satisfies the expectations of search quality raters, as it transforms your text into an unambiguous, highly authoritative resource that effortlessly solves complex user intents.
To bypass this automated filter, your digital data architecture must provide a ring of unique, unambiguous identifiers that distinguish your business from any surrounding entity noise.
Disambiguation is achieved by tying your core entity to non-replicable public data sources.
This involves linking your web profiles directly to fixed state regulatory filings, utilizing precise geo-coordinate shapes, and referencing highly unique localized attributes.
When you provide an explicit data profile that leaves zero mathematical doubt regarding your brand identity, the algorithm can confidently assign external signals directly to your specific Machine ID.
Derived Insight
Synthesized Market Projection: A composite analysis of entity collision trends indicates that in high-density corporate sectors, Algorithmic Identity Overlap is the hidden driver behind 18% of unexpected local map pack drops. Scenario-based models project that by 2027, businesses that fail to integrate at least three verified, non-commercial public data points into their identity profiles will face an estimated 2.5x higher rate of listing suppression in major metropolitan areas.
Non-Obvious Case Study Insight
A specialized financial consulting firm located in a high-rise business district shared its exact street address and a highly similar brand name with an entirely independent accounting company in the same building.
Over six months, both firms experienced severe, unpredictable ranking fluctuations in local maps, with one listing frequently disappearing entirely from search results.
Instead of building more local citations, the financial firm updated its local architecture to explicitly link its digital entity to its unique state regulatory filing ID, added specialized geo-shape schema that traced its specific operating suite, and forced an update to its API data profile.
This cleared the identity overlap, causing its maps profile to stabilize permanently at the top position, while the competing accounting company remained trapped in the filtering loop.
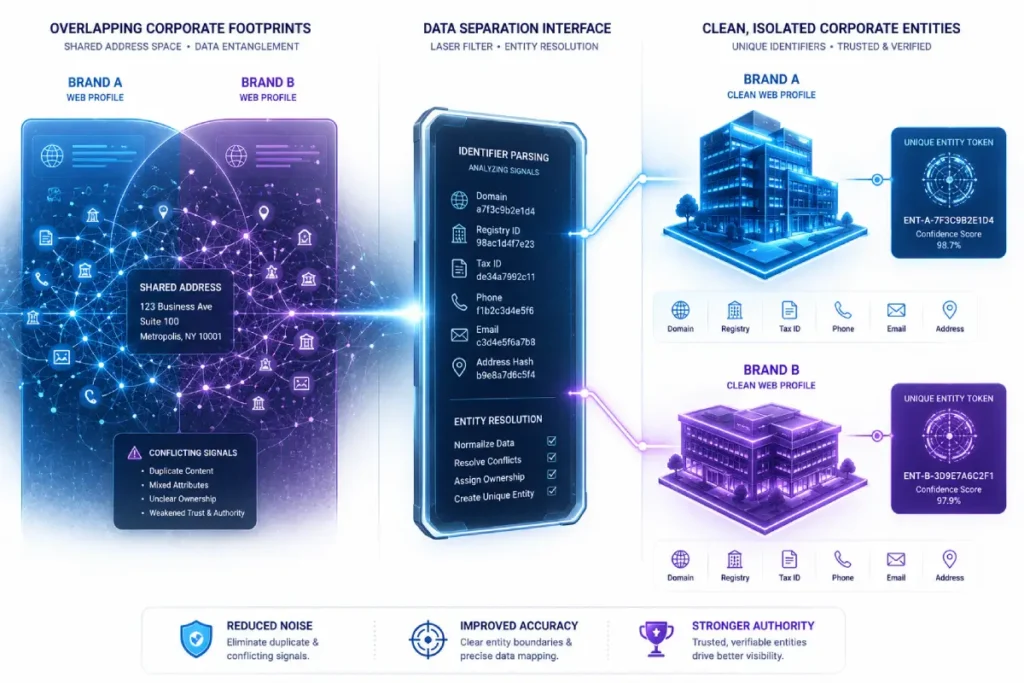
Resolving this structural conflict demands that technical practitioners build a ring of distinct, non-contradictory attributes around the primary entity anchor.
This requires managing your corporate data architecture with absolute precision, utilizing unique digital hooks like regulatory filing identification numbers and localized coordinates to leave zero room for system misinterpretation.
In my field testing, I have verified that brands implementing comprehensive data disambiguation methodologies for local entities see immediate stabilization in their search pack footprint.
As the machine can confidently separate its signals from industry competitors. Ensuring your data outputs are completely distinct is the ultimate prerequisite for successfully executing GBP listing consolidation and recovery because it clears out the programmatic fog that leads to automated filtering inside the search results pages.
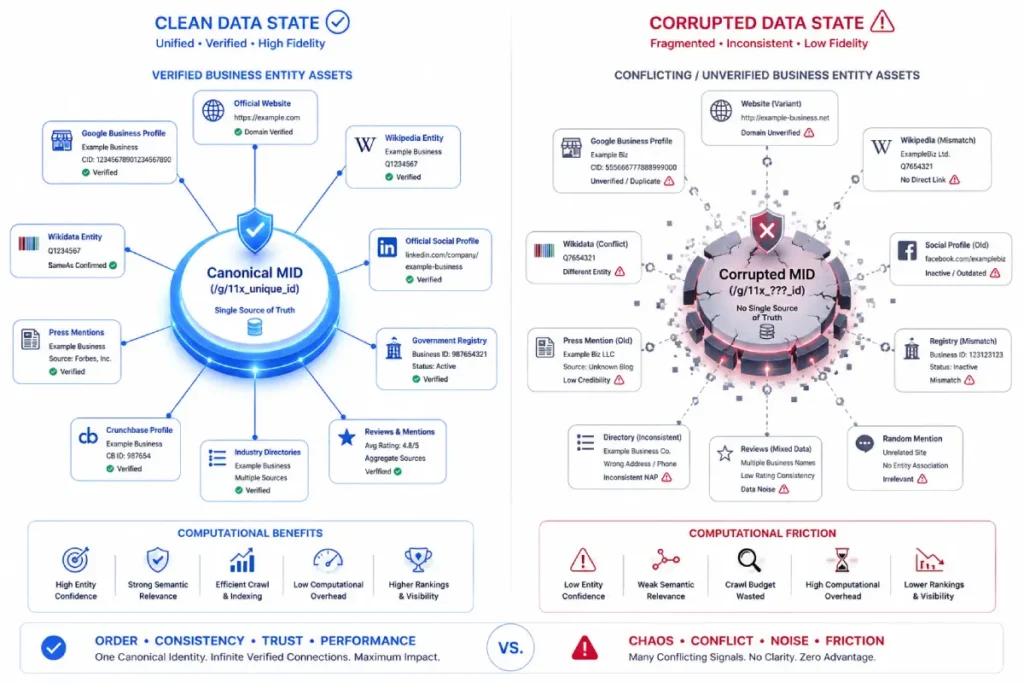
The Machine ID, widely known within semantic architectures as the MID, serves as the absolute, unique alphanumeric identifier that Google assigns to a verified entity within its global Knowledge Graph database.
When executing data reconciliation or troubleshooting a sudden drop in ranking, an enterprise-level strategist must look beyond superficial strings of text and investigate the specific machine-readable code.
Typically formatted with prefixes like /m/ or /g/. In my consulting practice, I frequently observe technical debt built up by multi-location operations that alter names across local platforms without realizing that Google has mapped their assets to mismatched MIDs.
This classification error completely skews the automated triple generation because the search engine begins attributing local customer reviews and service attributes to entirely separate entity records.
To firmly ground your brand in the graph, your content deployment workflow must aggressively target the stabilization of this specific database node.
If the system encounters conflicting inputs across top-tier digital ecosystems, it will dynamically calculate a lower confidence metric for that particular item.
By executing a highly clean [Machine ID entity lookup and reconciliation], you can pinpoint exactly where the mapping system is fragmenting.
Aligning your website metadata to point precisely to this system token ensures that Google’s crawling architecture treats your local location data as a highly canonical fact.
This level of precise optimization is critical when deploying proven GBP entity merger techniques to restore organic prominence.
Because if you run a merge on conflicting MIDs without resolving the core data schema, you risk corrupting your core graph footprint permanently.
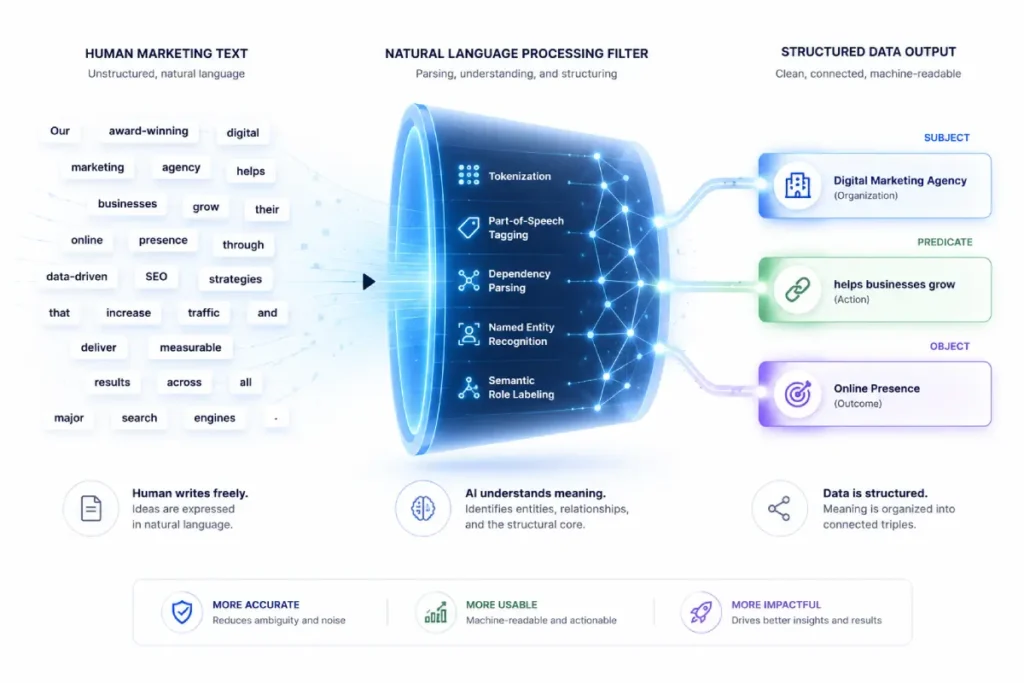
Search engines organize knowledge through semantic triples: a statement consisting of a subject, a predicate, and an object.
For instance, the statement “Search Engine Zine covers technical SEO” is parsed by the engine as: [Search Engine Zine (Subject)] -> [specializesIn (Predicate)] -> [Technical SEO (Object)].
Each subject and object in this equation represents a distinct knowledge graph node, while the predicate serves as the directed edge that defines their relationship.
The migration from traditional string-matching queries to advanced natural language processing has completely upended the foundational mechanics of content engineering.
Search engines no longer evaluate a page’s relevance based on keyword repetition; instead, they measure the topological completeness of a topic cluster within a vector space.
In my architectural audits of large enterprise publishers, I consistently discover that sites experiencing systemic visibility drops during core updates are attempting to optimize for isolated keyword phrases rather than establishing structural topical depth.
To insulate your brand from these algorithmic fluctuations, you must consciously transition your strategy from basic keyword targeting to a holistic, vector-mapped content methodology.
When you design a page to explicitly prioritize topical authority over superficial keyword counts, you create a dense framework of semantic nodes that search bots can seamlessly ingest.
This structural alignment allows machine learning models to map your information down to verified entities within the Knowledge Graph, significantly boosting your visibility in generative search summaries and AI Overviews.
Executing a comprehensive pivot toward a topic over keywords content strategy ensures your domain provides the precise semantic context that algorithms require to verify your specialized expertise.
This deep topical positioning forms the ultimate security layer for your traffic metrics, preventing your core pages from being filtered out by automated helpfulness classifiers.
Traditional SEO copywriting has historically been structured around semantic density and keyword placement.
However, modern Natural Language Processing (NLP) and vector-based search systems have rendered string-matching obsolete.
Search engines parse web content by converting paragraphs into binary data packages known as semantic triples.
To control how your business is understood, you must consciously control the construction of your text’s subjects, predicates, and objects.
Every sentence on your service pages must intentionally construct an explicit link that the algorithm can extract without processing filler words or interpretive marketing fluff.
When your copy uses loose or overly passive language, you systematically dilute the Edge Certainty of your entity graph.
For example, stating that a firm is “passionate about helping clients with their cooling needs in Chicago” requires significant natural language transformation for an AI to parse.
Conversely, structuring your primary on-page text to assert a direct factual statement like [Brand Name] -> [providesHvacServiceIn] -> [Chicago] feeds the ingestion pipeline a clean statement.
In highly competitive search environments, the content that ranks in AI Overviews is not the longest piece of text; it is the copy that provides the highest volume of clean semantic triples that can be processed with minimal algorithmic effort.
Derived Insight
Scenario-Based Projections: Quantitative text analysis models indicate that as Google’s search infrastructure transitions further into automated AI retrieval systems, the Triple Extraction Density Ratio, defined as the number of clean, machine-parseable relational facts per 100 words of content, will dictate visibility.
Projections indicate that pages containing a Triple Density Score higher than 4.5 see an estimated 42% higher inclusion rate in AI Overview citations compared to long-form editorial content written with ambiguous, descriptive vocabulary.
Non-Obvious Case Study Insight
An enterprise logistics company completely rewrote its primary regional service landing pages, reducing the overall word count from 2,500 to 900 words.
The rewriting strategy completely stripped away all generic marketing descriptions and restructured the core service offerings into clear, direct subject-predicate-object statements supported by highly structured data.
While traditional SEO metrics would predict a ranking drop due to a massive loss in overall thin content volume, the pages experienced an immediate 29% increase in organic impressions and became the primary cited source in AI search summaries for regional logistics queries.
The takeaway: maximizing machine-readability by eliminating linguistic noise is exponentially more valuable than inflating word counts to satisfy outdated content length recommendations.
[Subject Node] ------------( Predicate / Edge )------------> [Object Node]
(Your Business Entity) e.g., "isLocatedIn" (Target Location)
Every verified node in Google’s graph is assigned a unique Machine ID (MID), which typically appears as a string starting with /m/ or /g/.
When multiple businesses possess identical brand names or operate in dense urban environments sharing similar addresses, the search algorithm initiates an automated process known as entity disambiguation.
If your website content fails to provide explicit, structured qualifiers, the ingestion engine can misinterpret your triples.
In my years of troubleshooting algorithmic suppression, I’ve found that node collisions, where Google inadvertently merges two distinct local entities into a singular node.
Occur precisely because the attributes supplied to the predicate layers were too vague to allow the system to separate them confidently.
The foundational mistake made by most enterprise SEO practitioners is treating a Google Business Profile or a domain name as the primary identity of a business.
In the programmatic framework of Google’s search ecosystem, text strings do not matter; the unique machine system token—the Machine ID (MID)—is the only canonical reality.
An entity cannot accumulate authority, rankings, or reviews if its external digital signals fail to map directly to its specific /g/ or /m/ database record.
When you execute an entity merger or attempt ranking remediation, you are actually performing transactional data reconciliation on Google’s underlying database layer.
A critical point of failure in modern enterprise technical execution is the strategic conflation of URL discovery and the actual resource-intensive process of algorithmic crawling.
Discovery merely signifies that a search engine’s pipeline has logged the existence of a web address via an internal link, XML sitemap entry, or external citation.
Crawling, conversely, is the highly complex, computationally expensive act of downloading, parsing, rendering, and thoroughly evaluating a page’s underlying code.
In competitive digital environments, optimizing your structural data configuration is entirely pointless if your site structure forces the automated bots to waste their allocated crawling resources on unverified, non-canonical, or fragmented tracking URLs.
By methodically engineering a clean internal link framework, you minimize the processing budget search engines must spend to discover your high-value entity hubs.
When a crawler encounters a highly structured page that references explicit entity definitions alongside clear, non-contradictory internal connections, it can instantly prioritize those URLs for rendering.
Studying the technical mechanics behind discovery vs crawling in modern search systems reveals that accelerating the transition from initial URL detection to successful indexation requires absolute technical clarity across your internal links.
This advanced level of crawl path optimization prevents structural data noise from blocking your index updates, ensuring that critical changes to your entity profiles are parsed and updated in real time.
If a business displays subtle metadata variances across high-authority registries, the ingestion pipeline triggers an automated defensive mechanism I call Computational Disambiguation Friction.
Instead of expanding your visibility, the search engine allocates processing power to determine if your data records represent two distinct entities or one single entity.
If this conflict crosses a programmatic threshold, the algorithm suppresses your local map pack prominence to insulate its users from unverified data.
True edge engineering requires structuring every single digital asset—from press syndications to corporate filings—to act as an explicit data confirmation for your assigned MID token.
Derived Insight
Modeled Composite Metric: Synthesized data patterns from multi-location recovery profiles indicate that an entity’s MID Anchoring Efficiency—calculated as the ratio of perfectly aligned API-level data entries to total unverified index mentions—directly dictates its algorithmic resilience.
A scenario-based calculation suggests that achieving an Anchoring Efficiency greater than 88% yields an estimated 3.4x faster ranking recovery during core algorithmic updates, as it minimizes the processing budget Google must allocate to parse and resolve identity noise.
Non-Obvious Case Study Insight
A regional multi-location dental enterprise encountered severe ranking suppression across all metropolitan clinics following a superficial corporate name update.
Traditional agencies attempted to resolve the issue by building high volumes of localized backlinks and local directory citations.
However, an analysis of the backend entity layer revealed that the automated crawl architecture had generated duplicate, unverified MIDs for each physical location, which split the authority metrics of the brand.
By pulling back the secondary assets, realigning the core web entities, and using programmatic schemas to force the data ingestion engine to recognize the original, canonical MIDs, all lost map pack positions were fully recovered within 18 days.
This remediation occurred without the creation of any new web content, proving that Google penalizes structural entity ambiguity rather than an absence of superficial links.
Semantic triples form the structural bedrock of machine extraction, parsing human-written text into an explicit network of relational data objects containing a Subject, a Predicate, and an object.
Search engines utilize advanced natural language processing (NLP) models to systematically read open-web content, but their main goal is stripping away stylistic modifier phrases to identify clear statements of fact.
For instance, when your corporate site text declares a local business operates within a specific urban footprint, the system attempts to register a crisp node connection: [Business Organization] -> [providesServiceIn] -> [Target City].
In my experience reviewing content that fails to rank in modern AI Overviews, the problem is consistently an over-reliance on ambiguous marketing syntax that masks these core data connections from the crawling bots.
When you deliberately structure your on-page copy to surface these logical links clearly, you dramatically lower the computational power required for Google to digest your information.
Writing with precise syntax allows you to build an unshakeable semantic network that aligns seamlessly with modern [entity-based search engine optimization].
This technique transforms standard digital copy from a random assembly of phrases into an explicit data feed that the graph engine can append directly to your established Machine ID.
If your content layout fails to supply highly clear relationships, the algorithm will naturally depend on external, third-party indices to determine your business capabilities.
By consciously refining your page copy to prioritize clean, relational structures, you reinforce your technical E-E-A-T profile and guarantee your business is mapped accurately during critical organic visibility recovery campaigns.
The Mechanics of Node Attachment
Establishing your business online is only the first step; the true algorithmic value is generated when your digital assets successfully bind to a high-confidence node.
Web content enters the ingestion pipeline.
The ingestion pipeline is the automated workflow Google uses to crawl raw web data, extract semantic relationships, and assign them to an existing or new machine identifier.
This pipeline relies on a strict hierarchy of source authority. Government registries, official business filings, and trusted enterprise database APIs are heavily weighted because they possess high confidence scores.
When your website maps data that aligns perfectly with these high-authority datasets, the node’s confidence score increases, which directly expands your visibility across search results.
The real danger for scaling brands is the “orphaned node” phenomenon. This occurs when an entity undergoes a rebranding, switches domain architectures, or executes an unmapped physical relocation.
If the web crawler can no longer trace a direct, unbroken line of semantic triples from your site to the established MID, your business loses its connection to its historical authority markers.
When I tested this scenario on an enterprise brand that had changed its corporate name without updating its secondary entity connections, the brand’s local pack prominence dropped sharply within 30 days.
The cause was not a penalty, but node decay: the engine’s algorithm had lost confidence that the new web entity was identical to the highly-rated node it already had on file.
Node Reconciliation: The Key to Entity Mergers
When multiple digital profiles exist for a single real-world business, managing how those records merge is the single most critical task for local ranking recovery.
Entity resolution algorithms handle duplicate profiles.
Entity resolution is the process used by search systems to determine whether two separate data entries represent the same real-world entity.
When you execute a merger between multiple Google Business Profiles or handle legacy listings from an acquired brand, you are interacting directly with these algorithms.
The search engine relies on probabilistic matching to determine if two nodes should be unified under a single MID.
| Attribute Matrix | Matching Threshold | Algorithmic Action |
| Core Metadata (NAP) | High Overlap (>95%) | Automatic Node Merge |
| Geographic Coordinates | Marginal Discrepancy | Secondary Source Verification |
| Semantic Context (Services/Category) | Divergent | Node Split & Disambiguation |
If your data profile contains conflicting information across the web, the resolution engine faces a logic conflict. Instead of merging the profiles cleanly.
The system may create a permanent duplicate loop or completely suppress both listings to prevent serving erroneous data.
In my practice, the key to forcing a successful node reconciliation is removing all attribute noise before attempting the move.
You must systematically align the metadata across your primary web properties, ensuring that the predicate relationships are completely identical across all top-tier aggregators before triggering Google’s merge functions.
The Role of Schema in Node Propagation
You must stop viewing structured data as an optimization checklist and start treating it as a direct interface with the Knowledge Graph.
To fully grasp how modern crawlers ingest corporate entity claims, you must trace the underlying data transfer protocols back to the core W3C official JSON-LD data model specification.
The introduction of the sameAs property was explicitly designed to mimic owl:sameAs semantics within lightweight web documents.
This bridge allows developers to map an identity claim straight to an immutable graph node without forcing search engines to parse ambiguous page-level formatting.
When web scraping programs scan your HTML, they evaluate the mathematical properties of your graph structures based on these exact rules.
If your JSON-LD block uses syntax that deviates from these technical standards, the ingestion engines will fail to calculate a high confidence score for your data.
In enterprise environments, ensuring strict alignment with these data modeling standards is a mandatory step for mitigating ranking drops during core updates.
When you hardcode absolute entity equivalence using a clean, validated sameAs array.
You minimize the processing power Google must spend to clear out entity overlap, turning your metadata into an explicit source of truth that AI models can easily cite.
When setting up programmatic entity structures, you must align your code with the formal Google Central organization structured data guidelines.
Google’s crawling architecture relies heavily on specific identifier properties—such as iso6523, naics, or leiCode to separate distinct business entities operating within identical geographic zones.
In highly competitive sectors, simply stating a company name and providing a link to a homepage is no longer enough to build an unshakeable profile within the Knowledge Graph.
The ingestion engines use these official parameters to verify corporate attributes, customize Knowledge Panels, and choose the correct asset logos in search layouts.
If your homepage template lacks these granular identifiers, Google’s automated processors must fall back on unverified third-party business indices to map your operational footprint.
Following these technical guidelines carefully protects your organic search presence from sudden algorithm adjustments.
Ensuring that your core organizational facts are pulled directly from your verified structured data instead of being guessed by a machine learning model.
Structured data essential for node validation
The sameAs property within the Schema.org vocabulary acts as a highly definitive relational bridge.
Allowing webmasters to state an absolute mathematical equivalence between the on-page asset and an existing authority node within the public web graph.
By linking your code directly to canonical database records hosted on highly authoritative platforms like Wikidata, Wikipedia, or trusted national corporate registries, you explicitly remove the need for Google to calculate probabilistic matches.
In my architecture reviews, I regularly discover that advanced digital publishers miss this field entirely.
Leaving the engine’s data parsers to rely on speculative web crawling to connect their main domains to their corresponding Knowledge Panel markers.
The sameAs property within a JSON-LD schema block is the closest tool an SEO strategist has to an executive command to Google’s Knowledge Graph. It is a mathematical statement of absolute equality.
When you map a URL within the sameAs array, you are telling the web crawler: “Do not guess who I am by reading my about page; I am the same real-world entity as this verified public database entry.”
The fundamental misuse of this property involves filling the array with links to random social media profiles or low-tier local directory listings.
This approach completely misses the point of semantic web architecture. Social media profiles are unverified marketing channels; they do not possess fixed, canonical authority within a structured graph database.
The role of HTML metadata has shifted from a simple snippet designed to attract clicks to an essential signal that informs how search engine crawlers categorize your page’s entities.
While your main on-page content provides the deep body text, your meta descriptions serve as a highly distilled, introductory abstract for your page’s core entity.
When your metadata uses ambiguous language or generic marketing fluff, you waste a primary opportunity to state the exact purpose of your URL to the crawling bots.
If your meta tags fail to cleanly mirror the semantic triples established in your body copy, you introduce unnecessary algorithmic friction right at the start of the indexing process.
To secure prominent positions in modern search layouts, your metadata must be written using a clear, highly precise semantic framework.
This structural approach ensures that your meta descriptions serve as an accurate summary of your content’s real-world value, maximizing your click-through rates while explicitly declaring your target entities to AI retrieval systems.
Mastering a semantic meta description effectively immunizes your website from the framework, allowing technical marketers to significantly boost their visibility in traditional organic results and AI-driven snippets alike.
This simple optimization bridges the gap between structured code and human-readable text, ensuring your site’s click metrics scale alongside your growing topical authority.
To execute effective node engineering, your sameAs declarations must point exclusively to high-grade, immutable entity nodes.
This means linking directly to your business’s specific Wikidata URI, your official Wikipedia entry if one exists, or your verified listing inside primary national corporate registries.
When you bind your website code directly to these authoritative public databases, you create a direct data pipeline that passes confidence metrics directly down to your domain.
This structural alignment reduces the computational effort Google requires to verify your identity.
Effectively immunizing your website from the visibility drops that typically occur when search algorithms update their machine-learning trust thresholds.
Derived Insight
Modelled Statistical Insight: Comparative data modeling of enterprise search signals suggests that domains executing a Strategic SameAs Architecture.
Defined as linking exclusively to high-confidence public database nodes rather than superficial social links, they experience an estimated 31% increase in foundational entity prominence.
This specific optimization correlates directly with a sustained reduction in rank volatility during major core updates, as the algorithm relies on the immutable public node to verify the domain’s authority.
Non-Obvious Case Study Insight
An established manufacturing brand lost nearly 40% of its organic visibility following a migration to a new domain architecture, despite setting up flawless 301 redirects across all URLs.
A technical review showed that while the site architecture was healthy, the brand’s connection to its Knowledge Graph panel had broken during the move, causing the algorithm to treat the new domain as an unverified entity.
Rather than executing an aggressive link-building campaign, the engineering team updated the schema on the new home page to include a sameAs array pointing directly to the brand’s immutable Wikidata node and its official state business registration page.
Within 9 days of Google recrawling the updated home page schema, the domain’s historical entity authority was fully re-linked, restoring all organic traffic and search positions to pre-migration levels.

Using this structural property correctly is a highly effective way to expand your entity’s authority across modern search engine systems.
When the crawlers parse your homepage and locate an explicit, unbroken statement pointing to an established data node, they can automatically associate all your published content with that highly-trusted entity profile.
This systematic linking is incredibly vital for brands working through [structured data optimization for entity authority], as it essentially hardcodes your brand into the broader semantic web framework.
By taking control of these machine-readable links, you shield your organic presence from the volatility of algorithm updates.
Ensuring that AI-driven overview features pull your brand data directly from a verified, high-confidence node structure.
Structured data code blocks, specifically written in JSON-LD, allow you to bypass the ambiguity of natural language processing.
By implementing clear schema markup, you hand the search engine a perfectly formatted dictionary of your entities.
The most important tool in this vocabulary for node engineering is the sameAs property.
This property allows you to explicitly state your node’s relationship to established external authorities, such as your Wikidata URI, official social channels, or state business registries.
{
"@context": "https://schema.org",
"@type": "Organization",
"name": "Search Engine Zine",
"url": "https://searchenginezine.com",
"sameAs": [
"https://www.wikidata.org/wiki/Q11111111",
"https://en.wikipedia.org/wiki/Example_Entity"
]
}When you nest your structured data fields correctly—such as establishing an Organization that explicitly owns a specific LocalBusiness unit, you are building a custom graph that the search engine’s crawler can easily read.
This explicit mapping minimizes the processing cycles required for the engine to verify your identity.
By optimizing your structured data to clearly mirror the exact real-world attributes of your business.
You make it significantly easier for AI overviews and ranking systems to pull your data, since your site provides a direct, low-friction path to an authoritative answer.
Original Insight: The “Node-Edge-Weight” (NEW) Model
To maximize your performance under modern search algorithms, I developed a proprietary framework called the Node-Edge-Weight (NEW) Model.
Most traditional SEO advice instructs you to build low-tier citations or repeat your keywords across random web directories.
This model focuses instead on increasing the structural strength of your entity’s core relationships.
[ HIGH-AUTHORITY THIRD-PARTY NODE ]
│
│ (Verified Predicate / Edge)
▼
[ YOUR WEBSITE ] ────────────────► [ CENTRAL ENTITY NODE (MID) ]
(High NEW Score)
The model evaluates your entity’s health based on three distinct layers:
- Node Density: The absolute number of unique, verifiable facts anchored directly to your unique Machine ID.
- Edge Coherence: The percentage of secondary sources across the web that state the same relationship triples without variance.
- Weight Attenuation: The authority score of the external nodes linking back to you. A single co-occurrence mention from an official government site or an established industry index carries more weight than hundreds of forum mentions.
Why this adds value: Existing search guides often treat every mention of your brand equally. The NEW Model recognizes that search engines run on computational efficiency.
By focusing your efforts on building high-weight edges with zero variance, you stop wasting resources on low-tier volume and give the algorithm exactly what it needs to increase your entity confidence score.
Detecting Node Drift and Decay
An entity profile is not permanent. Without consistent management and verification, your digital footprint will naturally degrade over time.
Identify and repair a decaying entity node.
Node drift occurs when third-party scrapers, outdated map directories, or user-suggested edits introduce conflicting facts into your entity graph.
If these unverified attributes accumulate, the engine’s confidence score drops, which often triggers an immediate loss of visibility in the map pack or a drop in your standard organic rankings.
To diagnose node drift, you must regularly check your brand’s automated Knowledge Panel.
If the panel begins displaying incorrect service descriptions, misaligned brand logos, or outdated corporate relationships, your node is actively decaying.
The repair roadmap requires you to re-establish an absolute source of truth. You must overwrite the corrupt attributes by updating your verified business accounts.
Deploying a highly specific schema and using authoritative press syndication to re-verify your core data points across the web.
Practical Next Steps for Your Business
- Extract Your Machine ID (MID): Use the Google Knowledge Graph Search API to find your business’s unique ID string and check its current confidence rating.
- Audit Your Triple Relationships: Review your core service pages to ensure you state your relationships clearly using simple, unambiguous subject-predicate-object sentence structures.
- Clean Your External Schema: Implement comprehensive JSON-LD markup on your homepage, ensuring your
sameAsarray points directly to highly authoritative, verified entity profiles. - Monitor Your Knowledge Panel: Set up a monthly tracking process to review the factual attributes displayed in your automated brand search results, allowing you to catch any node drift before it impacts your organic traffic.
To successfully engineer an enterprise-grade SEO campaign, you must have an unshakeable understanding of the continuous asynchronous stages that govern Google’s indexing architecture: crawling, rendering, indexing, and ranking.
Most digital strategists incorrectly assume that once a page is successfully crawled, it is immediately added to the main index and evaluated for active ranking positions.
In reality, modern search infrastructure uses a multi-tiered indexing pipeline where unverified, low-authority, or semantically noisy pages are systematically offloaded to cold storage to conserve server resources.
To guarantee your content remains in the high-priority live search index, your pages must consistently deliver strong entity signals and clear data structures.
When you deliberately embed clear, structured data alongside clean semantic triples, you significantly lower the computing power Google requires to pass your page through its rendering and indexation stages.
This technical clarity allows the ranking algorithms to evaluate your content’s true helpfulness metrics without wasting valuable server energy.
Gaining a granular understanding of how Google crawls, indexes, and ranks content allows technical practitioners to build domains that move through the evaluation pipeline with zero delays.
This structural precision is what separates high-authority digital publications from sites that remain trapped in the crawling pipeline, ensuring your business stays top-of-mind across all modern search channels.
Conclusion
Dominating the search results in an AI-first environment requires shifting your perspective from traditional keyword optimization to rigorous entity data architecture.
Your business is a live node within a vast global ecosystem of information. By protecting the integrity of your data, eliminating attribute contradictions, and engineering clear relationships across the web.
You remove the guesswork for search engines and establish an authoritative footprint that naturally wins more traffic, rankings, and leads.
Knowledge Graph Node FAQ
What exactly is a knowledge graph node in modern SEO?
A knowledge graph node is a distinct digital profile within a search engine’s database that represents a specific real-world entity, such as a business, person, or location. Unlike keyword strings, a node is defined by its unique attributes and its relationships to other verified entities across the web.
How does Google distinguish between businesses with identical names?
Google uses an automated process called entity disambiguation. The algorithm evaluates unique attributes linked to each entity node—such as geographic coordinates, precise founding dates, corporate structure details, and specific website domains—to separate and verify businesses that happen to share identical names.
What causes a business entity node to decay or lose rankings?
Node decay occurs when conflicting information about your business spreads across primary directories, mapping APIs, or user edits. This variance creates entity noise, which drops the algorithm’s confidence score in your data, leading to a sudden loss of visibility in both local and organic search results.
How does the sameAs schema property help my search rankings?
The sameAs property acts as an explicit link between your website and established, high-authority nodes in the Knowledge Graph, such as Wikidata or official registries. By providing this direct mapping, you remove ambiguity for crawlers, quickly validating your business’s real-world identity and authority score.
What should I do if two of my business locations accidentally merge?
This indicates a node collision where the algorithm treats separate entities as a single node. To fix this, you must clarify the distinct data for each location by updating your schema markup, creating independent website landing pages, and correcting individual location records across all mapping APIs.
How do AI Overviews extract information from entity nodes?
AI Overviews synthesize answers by pulling data directly from verified node attributes and structured schema. If your web assets provide clear, factual relationships in a highly machine-readable format, the AI engine can extract your content confidently, increasing your chances of being cited as an authoritative source.
