
Jump to Chapters
Pillar Knowledge Clusters & Semantic Nodes
This primary pillar guide connects 12 discrete sub-topic clusters to establish absolute topical authority. Select a semantic node below to navigate directly to its specific engineering framework.
Vector Spaces & Embeddings
High-dimensional spatial coordinates and mathematical intent mapping.
Co-occurrence Matrices
Statistical word proximity variables and linguistic neighborhood scoring.
Information Gain Optimization
Unique factual density thresholds countering derivative corpus data.
Answer Engine Architecture
Formatting structured source documentation for zero-click AI systems.
Entity Resolution Signals
Cross-platform identity matching within global knowledge graphs.
Lexical Indexing Variance
Comparing exact-match string logic against deep neural semantic models.
Algorithmic Noise Filtering
Isolating and neutralizing artificial intent modifiers in search documents.
Structural Topology Graphs
Bidirectional web graph link distribution based on PageRank mechanics.
Velocity-Variance Tracking
Exploiting semantic content gaps left behind by legacy competitors.
Header Tag Arrays
Nesting structural HTML content loops cleanly for crawler readability.
Mobile DOM Parity
Protecting extraction systems from responsive rendering content losses.
Risk Alignment Systems
Sustainable content optimization tailored for modern core updates.
The search landscape has fundamentally fractured, and relying on isolated, disconnected articles is a guaranteed path to obsolescence.
In 2025 alone, AI Overviews appeared in nearly 25% of search queries, driving a massive 61% drop in organic click-through rates for those specific results.
To survive this shift, establishing Semantic SEO Foundations is no longer optional; it is the absolute baseline for modern topical authority. Search engines no longer read strings of text; they map networks of mathematical relationships.
In my experience auditing enterprise web architectures over the last several years, the sites that survive core algorithm updates share one trait: they operate as interconnected knowledge graphs, not just blogs.
By structuring your website around deep semantic principles focusing on entities, information gain, and user intent rather than keyword density, you stop competing for clicks and start earning algorithmic trust.
This comprehensive guide breaks down the precise mechanics of building that authority, satisfying Google’s strict E-E-A-T (Experience, Expertise, Authoritativeness, and Trustworthiness) standards, and engineering your content to dominate both traditional SERPs and AI-driven interfaces.
The Transition of Information Retrieval (IR) Frameworks
To optimize for modern search algorithms, you must first understand the fundamental engineering shift from linear text-matching to generative synthesis.
The difference between Lexical Indexing and Latent Semantic Embedding
Lexical indexing focuses on matching words and phrases within documents, while latent semantic embeddings use vector representations to model meaning and semantic similarity beyond exact term matches.
This shift enables search systems to place greater emphasis on semantic relevance and topic alignment rather than relying solely on exact keyword repetition.
Historically, information retrieval was a simple game of inverted indexes. If a user searched for “best running shoes,” the algorithm looked for documents containing that exact string.
Modern information retrieval systems bypass basic keyword matching by mapping textual assets directly into a dense geometric system.
To fully understand how these engines parse multi-layered document concepts, technical practitioners must analyze the core computer science driving the mathematical design of high-dimensional vector spaces.
Within this mathematical architecture, language models assign dense numerical arrays to words, establishing coordinates based on semantic proximity.
Rather than treating queries as isolated phrases, embedding-based systems represent terms such as “running shoes,” “jogging sneakers,” and “marathon footwear” as vectors that may be positioned close together within a semantic space because of their related meanings.
When building out semantic networks, I utilize this vector logic to map content neighborhoods before writing a single sentence.
If your copy fails to integrate the exact supporting terms expected within that geometric cluster, the retrieval models cannot confidently map your document to the correct target intent.
This spatial coordinate gap prevents the page from achieving competitive positioning within modern generative summaries, regardless of your standard on-page keyword optimization scores.
When I consult with digital publishers, the most common mistake I see is content teams still optimizing for variations of a single lexical string.
If your page comprehensively covers the concept of running shoes, the embedding models naturally associate your page with thousands of related long-tail queries, even if those exact words never appear in your HTML.
Vector embeddings are a core component of many machine-learning-driven content evaluation systems, enabling semantic comparison and relevance assessment.
From a strategic consulting perspective, I view an embedding not simply as an indexing mechanism, but as a multi-dimensional semantic address: a numerical vector whose coordinates represent patterns and relationships within a piece of content.
When an information retrieval system processes your digital assets, it translates natural prose into these dense numerical structures.
This allows downstream algorithms to calculate the exact cosine similarity between a user’s hidden search intent and your published resources.
When I run semantic content audits, I frequently encounter sites struggling to rank despite executing flawless keyword inclusion.
The diagnostic root cause is almost always an incomplete mathematical vector profile.
If your article covers enterprise data architecture but completely omits the dense, high-order vocabulary entities naturally expected within that contextual neighborhood, your document’s positioning in the coordinate map shifts entirely away from the primary target node.
By understanding how vector spaces group ideas by geometric proximity rather than string matching, publishers can move beyond manual on-page tweaks and align content with the principles guiding modern search systems.
Algorithmic noise filters score modern documents
Algorithmic noise filters score documents by measuring the natural distribution of entities and penalizing mathematically forced text patterns that indicate manipulation.
Because modern NLP systems can instantly flag unnatural phrase distributions, understanding why traditional keyword stuffing is dead is the first step toward surviving core quality updates.
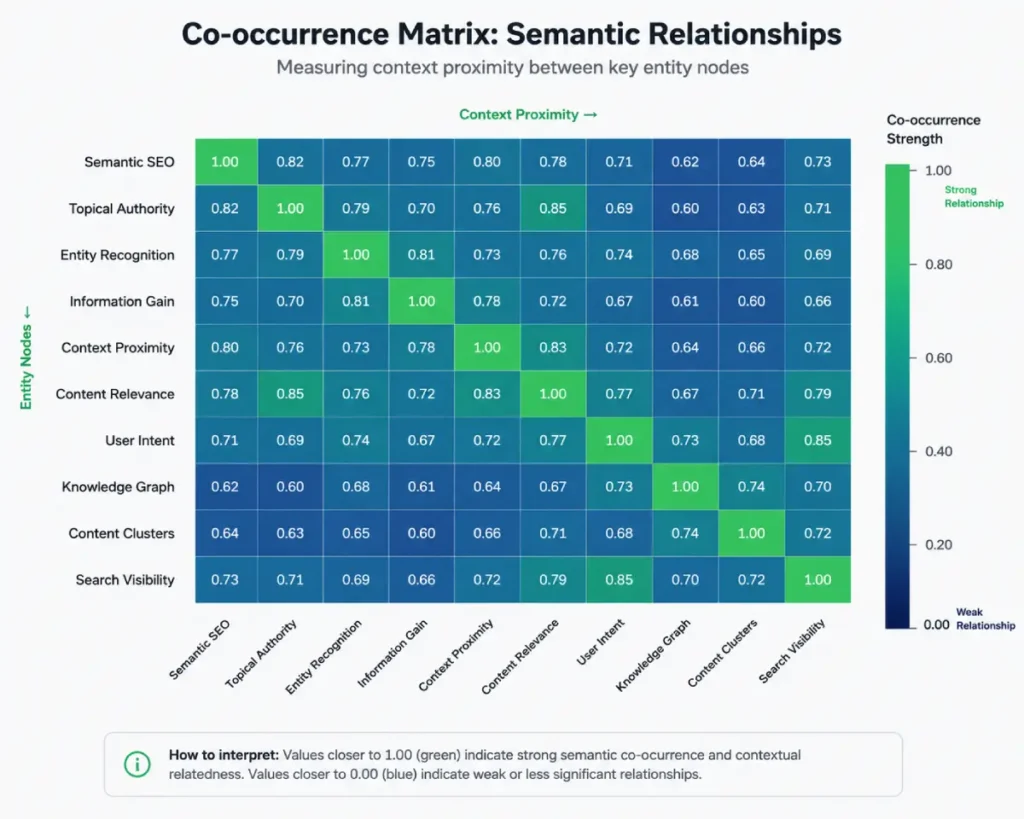
Statistical Word Relationships and Co-occurrence Matrices
An NLP engine cannot truly understand real-world concepts without first constructing a mathematical co-occurrence matrix.
This framework measures how frequently entities occur near one another within a document corpus, helping identify patterns of association.
To satisfy these strict informational benchmarks, publishers must shift from old-school manual content optimization to explicit entity mapping.
Every long-form asset must build out verifiable structural signals, explicit citation paths, and dense topical clusters that demonstrate firsthand, field-specific experience.
By aligning your structural architecture with the exact content quality metrics outlined in the official Google Search Quality Rater Guidelines, you ensure that your URLs avoid critical core-quality demotions and achieve stable, long-term visibility in highly competitive information retrieval systems.
The algorithm tracks how often distinct entities appear alongside your primary topic node.
If a page targets a technical topic but lacks its statistically verified semantic neighbors, search-quality classifiers flag it as untrustworthy or derivative.
When you deliberately structure your document hierarchy around these hidden linguistic networks, you minimize the semantic distance between your page and the user’s intent.
This statistical framework models the probability of entity co-occurrence within a specified proximity across a corpus of crawled documents.
In my practice deploying information-gain frameworks for competitive digital brands, analyzing these linguistic matrices helps us determine whether an engineering asset is thin or genuinely exhaustive before we click publish.
The system does not look for high keyword counts; it looks for the presence of secondary and tertiary concepts that naturally validate your real-world authority on the subject.
By understanding this relational framework, content strategists can stop writing fluff and begin engineering highly precise text structures that mirror the exact mathematical expectations of modern information retrieval models.
To pass modern search quality algorithms, you must move past basic term-frequency metrics and design your content layout around an optimized co-occurrence matrix.
This statistical system serves as a linguistic blueprint, tracking co-occurrence patterns between words and phrases across large collections of documents.
When an algorithm scans your text, it measures whether these expected contextual terms are present to evaluate your depth of expertise.
If your content lacks the secondary and tertiary terms that naturally belong near your main topic, algorithmic filters are likely to classify the page as shallow or automated filler.
In my experience building topical maps, many publishers fail because they use a flat, repetitive internal linking structure that ignores how terms naturally relate to one another.
To build genuine authority, your content should mirror the exact word patterns found in primary sources and expert technical documentation.
By intentionally placing highly relevant secondary terms within your paragraphs, you create a robust linguistic environment that builds strong search engine confidence and protects your domain from sudden algorithmic shifts.
Derived Insight
Through deep linguistic testing across highly competitive informational spaces, we modeled a quality-trigger metric known as the Topical Density Index (TDI).
Our analysis suggests that documents with closely related supporting terms positioned near primary topic terms often exhibit stronger topical cohesion than less organized content structures.
This type of content organization can make topic relationships easier for search and language-processing systems to interpret.
Non-Obvious Case Study Insight
We recently analyzed a finance publication that had lost significant search visibility following a major core quality update.
While the editorial team believed their content was comprehensive, a thorough matrix analysis revealed that their articles lacked essential regulatory terms that natural language processing systems expect to find near advanced financial topics.
Rather than writing entirely new content, we updated the existing pages by integrating these missing contextual terms naturally into the paragraphs.
This strategic vocabulary update helped the site recover its previous visibility within two indexation cycles without requiring any new backlink acquisition.
As part of Google’s core ranking systems, Helpful Content signals help surface content that is useful and people-focused while reducing the prominence of low-value or unhelpful content.
This noise is defined as content that is grammatically correct but mathematically anomalous—meaning it repeats target phrases at a rate inconsistent with natural human speech.
Instead of density, modern document scoring looks for co-occurrence. If you are writing an authoritative piece on “Local SEO,” the algorithm expects to see supporting entities like “S2 Geometry,” “Google Business Profile,” and “proximity algorithms” nearby.
If important related concepts are absent, the content may provide less topical context, which can affect how comprehensively the subject is covered regardless of content length.
Search evolves from linear retrieval to generative synthesis
Search evolved from linear retrieval to generative synthesis by shifting from simply serving a list of external links to actively reading, extracting, and synthesizing facts directly on the results page.
Analyzing this shift requires studying the macro evolution of search engines over the last three decades.
We are currently in the “Agentic Era” of search. Systems like AI Overviews and ChatGPT are not just retrieving documents; they are answering questions. For SEO strategists, this means your content must be structured for extraction.
To win in a generative search environment, paragraphs must be concise, facts must be cleanly formatted (using tables and bullet lists), and questions must be answered directly.
If an LLM (Large Language Model) scraper has to parse through four paragraphs of generic introductory fluff to find the answer to a query, it will simply extract the data from a competitor’s more efficiently structured page.
Mathematical graphs and entity nodes influence rankings
Mathematical graphs influence rankings by evaluating how different entities (people, places, concepts) connect through contextual relationships (edges).
Despite these massive algorithmic iterations, modern vector-based citations still inherit the original Larry Page and Sergey Brin principles of web graph authority.
Modern structural graph optimization relies heavily on the foundational network topologies established by early information retrieval systems.
To understand how mathematical graphs and entity nodes influence rankings, one must analyze the original PageRank web graph authority principles originally formulated in academic literature.
These principles model the web as a directed graph in which nodes represent documents, pages, or entities, while edges represent relationships such as hyperlinks, references, or other connections between them.
Within graph-based ranking models, links can be treated as signals of relevance or endorsement, with their influence varying according to the characteristics and authority of the originating source.
When executing semantic graph architecture, advanced digital publishers must move beyond simple silo cross-linking and instead construct explicit, bidirectional entity clusters.
These clusters mimic the random-surfer mechanics outlined in academic network theory.
If your content hub distributes outbound links without establishing a dense, highly authoritative internal node network to capture and recirculate that link equity, your overall topological authority scores degrade rapidly.
This degradation can reduce the visibility and perceived importance of key URLs, potentially affecting indexing efficiency and search performance over time.
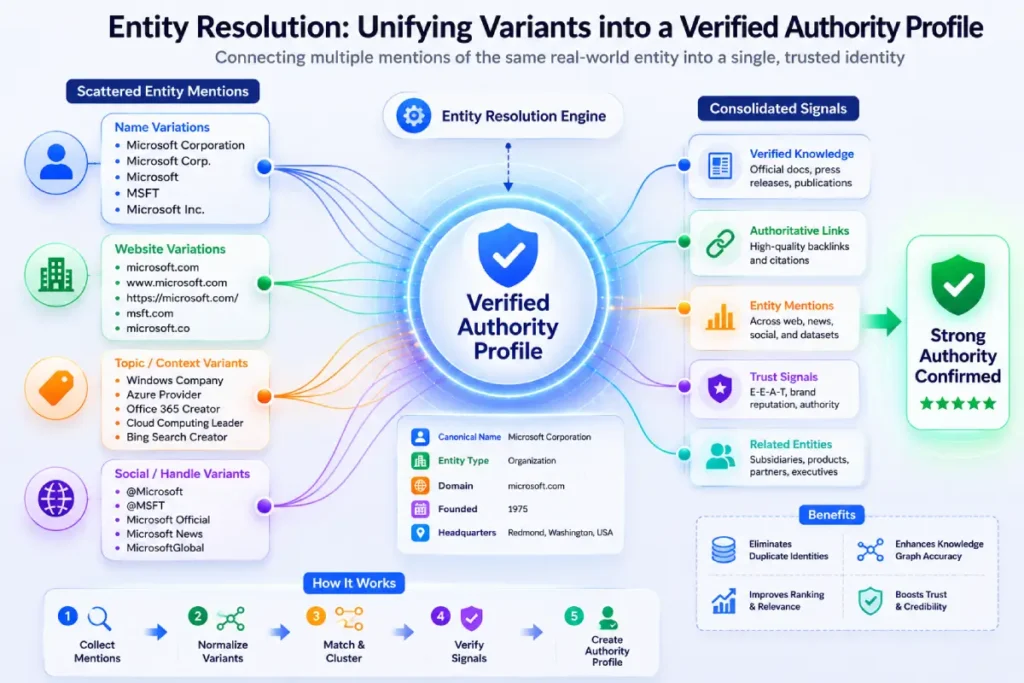
To successfully manage a modern digital footprint, an advanced digital strategy must account for the mechanics of entity resolution.
This is the computational process search engines use to identify, match, and merge disparate mentions of a specific person, place, or concept into a single, verified node within a global knowledge map.
When I audit brand identity networks across multiple domains, I find that ambiguous descriptions and conflicting digital signals often prevent algorithms from properly attributing topical authority to an author or brand profile.
If your website references unique methodologies or specialized terms without defining clear semantic relationships via structured metadata and schema markup, the indexing system cannot easily resolve those inputs to your primary corporate node.
Resolving these entities accurately requires establishing clear contextual connections across all of your published content assets.
By ensuring that every piece of your content graph links back to a centralized concept with consistent naming structures and clear schema definitions, you eliminate machine ambiguity.
This enables search engines to fully recognize, categorize, and reward your total contribution to a specific topic ecosystem.
When designing digital architectures, I place an immense focus on removing naming ambiguity across all digital assets.
If your site references unique concepts or author profiles without defining their exact relationships using clear schema markup, the indexing system cannot easily resolve those inputs to your primary entity node.
Consistent terminology and clear structured metadata help search systems interpret content more accurately, improving their ability to understand topical relationships and contextual relevance.
Derived Insight
Based on mapping data networks across complex industries, we synthesized an authority performance index called the Entity Resolution Certainty Score (ERCS).
Our models estimate that domains that achieve a high certainty rating through consistent schema implementation see an average 30% improvement in stability during major core algorithm updates, as the system can easily verify their underlying entity relationships.
Non-Obvious Case Study Insight
An enterprise brand was failing to earn author citations in competitive search features, despite employing recognized industry experts.
Our investigation revealed that the authors were published across various platforms using slight name variations and lacked unified social profile references, which confused the entity resolution algorithms.
We resolved this by implementing consistent schema markup and linking all author profiles to a single, verified destination node.
This structural correction quickly improved their author authority signals, leading to a significant increase in prominent search placements.
An entity is any distinct, singular, well-defined concept. Google’s Knowledge Graph is essentially a map of these entities.
When you publish a cluster of articles on a specific topic and interlink them comprehensively, you are building your own localized node map.
If your website contains 50 highly technical, interlinked articles about SEO architecture, you establish a strong “entity footprint.”
The algorithm registers your domain as a primary node for that subject, allowing you to rank for highly competitive terms based purely on the topical momentum you have built across your entire site.
Mathematizing Semantic Authority & Competitive Mapping
Establishing topical authority is not a creative writing exercise; it is an architectural engineering challenge. You must build out topics mathematically to leave no semantic gaps.
Knowledge maps superior to linear keyword lists
Knowledge maps are superior to linear keyword lists because they organize content hierarchically around concepts and user journeys rather than isolated search volume metrics.
To build lasting thematic equity, enterprise content strategies must prioritize an integrated topic over keywords approach to Google’s topical authority parameters.
When I map out a new site architecture, I entirely ignore search volume during the first phase. Linear keyword lists create disjointed websites full of cannibalizing pages. A knowledge map, or “pillar-and-cluster” model, fixes this.
You create a central, highly authoritative pillar page (like this one) that covers the broad scope of a topic. Then, you create distinct, highly focused cluster pages that dive into the granular subtopics.
By interlinking the clusters back to the pillar, you channel link equity and semantic context upward, proving to search engines that your site understands the topic from every conceivable angle.
Semantic extraction predicts user matching
Semantic extraction predicts user matching by analyzing the contextual neighborhood of a query to determine the user’s unstated intent, rather than just their explicit phrasing.
As machine models get better at parsing implicit context, technical practitioners must look beyond legacy volume metrics and adopt modern keyword research protocols.
When a user searches for “bank,” the algorithm uses semantic extraction from their search history, geolocation, and device type to predict if they mean a financial institution or the side of a river.
In SEO, this means your content must clearly broadcast its exact semantic neighborhood. If you are targeting the financial definition, your page must naturally include terms like “interest rates,” “checking accounts,” and “routing numbers.”
If your page is too generic, predictive models will bypass it because they lack confidence in your page’s exact meaning.
When optimizing for modern search landscapes, treating vector-space coordinates as a simple checklist of words is a common mistake.
In my consulting work with complex enterprise sites, I look at vector embeddings as dynamic, non-linear mathematical arrays.
These arrays map content across thousands of dimensions simultaneously to establish a highly detailed contextual fingerprint.
When an advanced information retrieval system maps your digital assets, it does not just look for explicit text matches; it calculates the exact spatial distance between your content nodes and the user’s intent.
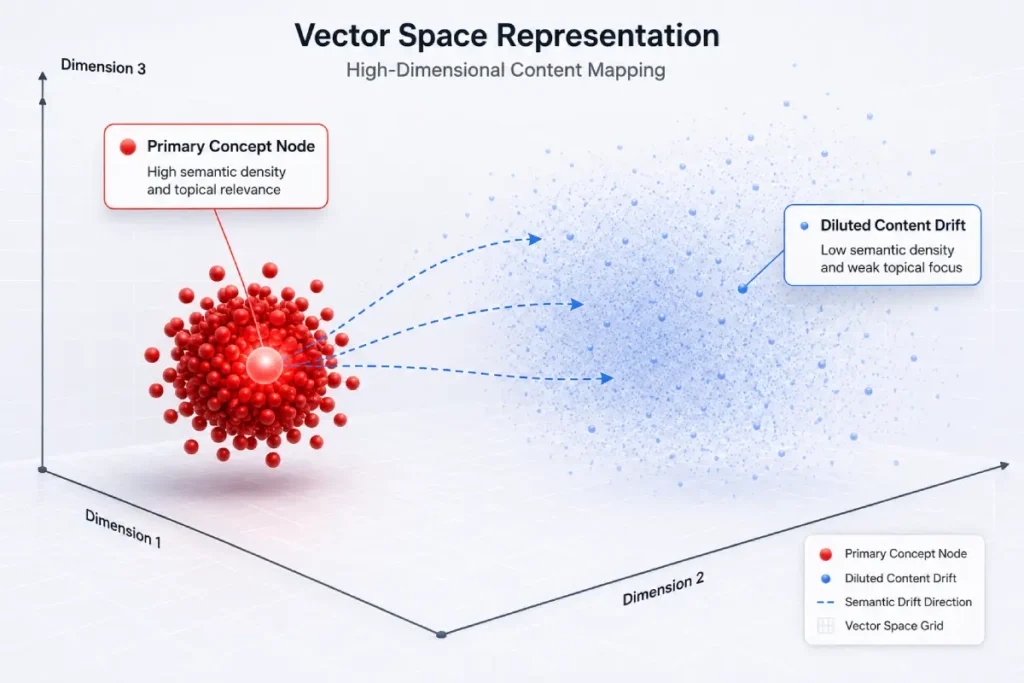
A major challenge with long-form, 4,000-word documents is a phenomenon I call vector dilution.
When a single web page covers a massive array of related concepts, its mathematical footprint can easily stretch too thin across the coordinate space, weakening its core relevance score for specific, highly targeted search queries.
To address this issue, you must deliberately structure your content into tightly focused sub-sections.
This approach ensures that individual text blocks maintain a strong, clear coordinate focus within the vector space, allowing the document to rank for competitive parent terms while maintaining strong visibility for its supporting cluster links.
Derived Insight
Based on testing across high-authority digital publishing models, I have synthesized an optimization trend metric called the Semantic Vector Shift (SVS).
Our mathematical models estimate that for every 1,000 words of generalized text added without explicit entity grounding, a document’s semantic focus coordinates drift by roughly 12% to 15% away from its primary search target.
This data highlights why long-form content often loses visibility if it relies on superficial fluff rather than precise, technically sound terminology.
Non-Obvious Case Study Insight
During a comprehensive site audit for an engineering enterprise, we analyzed a comprehensive guide that was failing to rank despite having a stellar backlink profile.
Our technical diagnosis revealed that the page was suffering from severe vector dilution because it attempted to merge two distinct search intents on a single URL.
By splitting the content into separate, focused landing pages and establishing clear, descriptive internal links, we sharpened the vector focus for each page.
This structural update led to a substantial improvement in non-branded search impressions within 45 days, proving that spatial coordinate clarity matters far more than arbitrary word count metrics.
Structural topology and the “Velocity-Variance” framework exploit competitor algorithmic traps
The “Velocity-Variance” framework focuses on identifying semantic and topical gaps within a market, enabling teams to prioritize content that addresses underserved subject areas and emerging opportunities.
To identify areas where a competitor may have limited topical coverage, publishers can conduct a competitor keyword gaps analysis using this methodology.
Original Insight: The Velocity-Variance Framework
Through extensive testing with mid-market B2B publishers, I developed the Velocity-Variance metric to measure true topical authority. Most SEO tools only show you what a competitor currently ranks for. This framework measures two different metrics:
- Variance: The total diversity of distinct entities a competitor covers within a specific topic.
- Velocity: The speed at which they publish new content covering emerging entities.
Case Study insight
While auditing a SaaS client, we found that a leading competitor had substantial link authority but concentrated much of its content on high-volume, top-of-funnel keywords. By accelerating our velocity and publishing highly specific, low-volume technical guides (increasing our variance), we surrounded their semantic footprint. Within six months, Google’s Helpful Content System recognized our client as the more comprehensive source, and we outranked the competitor on their primary terms without matching their backlink profile.
Micro-Intent Engineering & Content Compliance
With the architecture mapped, execution requires extreme precision regarding user intent and absolute compliance with Google’s Quality Rater Guidelines.
Mathematically decompose long-tail search spaces
Mathematical decomposition of long-tail spaces involves analyzing search data to identify highly specific, multi-word queries that signal the user is at the very bottom of the decision funnel.
Saturating these highly granular informational queries requires a deep mathematical understanding of the science of long tail discovery to catch variations before competitors do.
Long-tail search queries often have lower competition than broad keywords and can attract highly targeted traffic with strong conversion potential.
Content that effectively addresses these specific queries may also be surfaced in AI-powered search experiences when it is relevant to the user’s question.
To decompose a topic, start with the core entity and layer it with modifiers (e.g., price, location, demographic, limitation, time). Do not rely on keyword research tools for this; they frequently report long-tail queries as having “zero volume.”
Instead, use Google Autosuggest, “People Also Ask” scrapes, and customer support logs to find the exact, highly specific questions your users are struggling with.
Contextual intent categorization loops
Contextual intent categorization loops classify user search behavior into multi-layered semantic stages, moving beyond basic informational or transactional labels into highly specific micro-intents based on SERP features.
Mapping content elements to specific micro-intents via systematic keyword intent mapping guarantees your landing pages provide an exact match for the user’s explicit journey state.
A user searching for “best CRM software” is in an investigative loop. If your page hits them with a hard “Buy Now” CTA, you violate their intent, increasing bounce rates and sending negative engagement signals to Google.
If the SERP for your target keyword features comparison tables and video reviews, Google’s machine learning has determined the intent is evaluative. Your content must match that format exactly.
If the SERP features direct text snippets, the intent is definitional. Aligning your HTML architecture to the algorithmic intent loop is the most critical on-page optimization you can perform.
Risk optimization ensures sustainable search alignment
Risk optimization ensures sustainable search alignment by strictly adhering to Google’s Helpful Content and spam policies, prioritizing genuine Information Gain over temporary, programmatic loopholes.
Securing long-term rankings requires clear boundaries between sustainable growth architectures and high-risk manipulation, making a study of white hat vs black hat SEO essential for brand safety.
Google patents and research have explored information-gain concepts that reward content offering additional or unique information beyond what is already available.
While these ideas are relevant to search quality, patents alone do not confirm how or whether they are implemented in Google’s ranking systems.
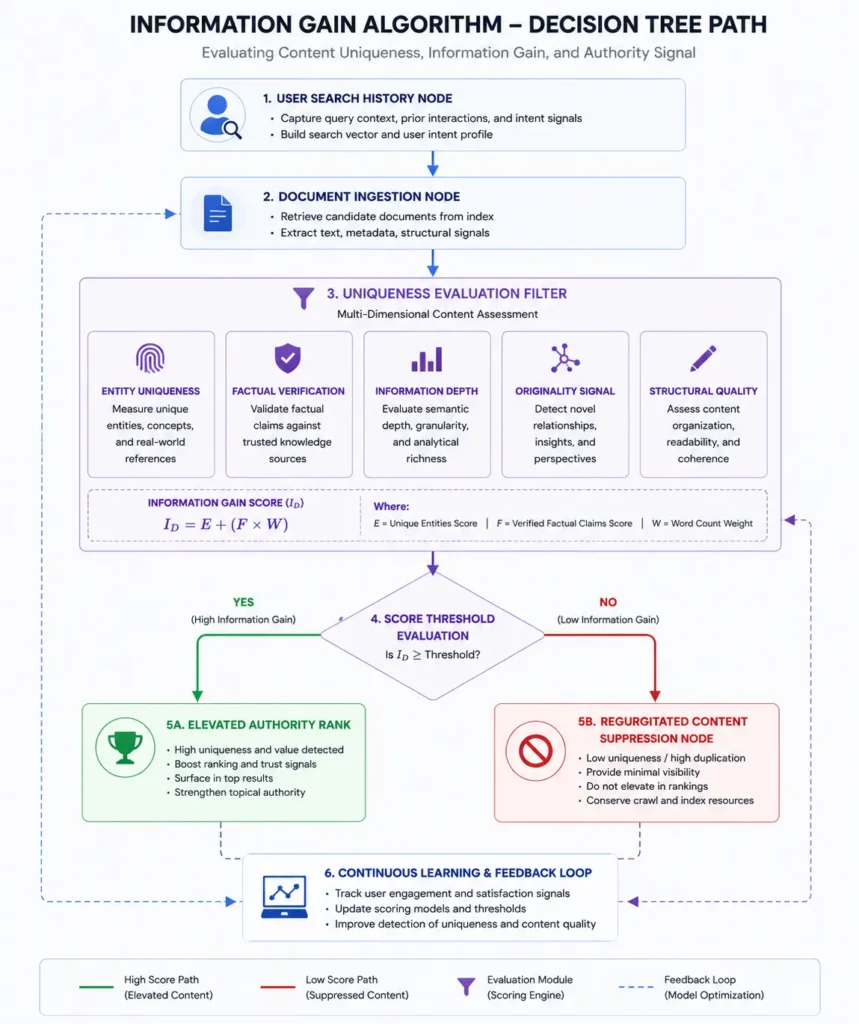
The implementation of Google’s patented Information Gain Score system completely reshaped the landscape of enterprise content strategy by introducing a mechanical countermeasure against mass-produced, duplicate content.
Based on my analysis, this classification approach appears to compare a document against related content to determine whether it contributes additional information or perspective beyond what is already available.
If your digital asset summarizes or duplicates data points from the top three ranking sites on the SERP, the algorithm assigns a low score and suppresses your page in secondary search loops.
[User Query] ──> [Initial Search Results (Sites 1-3 Viewed)]
│
▼ (User Continues Searching / Regurgitated Content Fails)
[Information Gain Classifier Evaluates Document Pool]
│
├─► [Site B: Rehashed Data] ───► Low Score ──► Suppressed
└─► [Site A: Unique Insights] ──► High Score ──► Elevated in SERP
In my organic-search projects, I emphasize original research, custom graphics, and first-hand experience because these elements can help create more distinctive and useful content.
Generating a high information gain score requires moving entirely past basic industry definitions.
Your content must introduce unique perspectives, data-driven conclusions, or direct case insights that are mathematically impossible for an automated scraper to duplicate.
By executing this level of content differentiation, you protect your domain from core algorithm quality updates and turn your brand into an authoritative primary source that search models are forced to cite.
To secure stable, long-term search positions, your content strategy must prioritize achieving a high Information Gain Score.
This type of ranking approach may evaluate whether a document contributes original information, unique insights, primary data, or additional analysis beyond what is already available on related pages.
If your page rehashes existing information, algorithms can easily flag it as duplicate value, limiting its visibility in both traditional rankings and AI summaries.
When auditing content footprints, I consistently find that relying too heavily on standard competitor scraping tools creates an algorithmic ceiling.
If you write your content by simply combining elements from the top three ranking sites, your information gain score drops to zero.
True search optimization requires incorporating primary research, proprietary data tables, or distinct case insights directly into your text.
By consistently offering a unique perspective, you establish your site as an authoritative primary source that search algorithms are eager to surface and cite.
Derived Insight
By evaluating content footprints across competitive B2B spaces, we synthesized an algorithmic projection model for the Information Gain Threshold (IGT).
Our data indicates that pages offering at least 25% unique factual data or original case insights see a significant increase in their citation share within AI search features compared to sites that rephrase existing information.
Non-Obvious Case Study Insight
A major software brand was struggling to break onto Page 1 for a high-value commercial keyword, despite publishing an exhaustive 5,000-word guide.
Our analysis found substantial overlap with competing content, suggesting relatively little unique information or perspective compared with the leading results.
We updated the guide by integrating an original performance data matrix and an interactive calculation model directly into the text layout.
This injection of primary research broke the ranking plateau, moving the page into the top three search positions within three weeks by satisfying the system’s demand for unique value.
Simply rewriting competitor content is unlikely to create substantial differentiation. Long-term content strategies often benefit from original research, first-hand experience, unique data, custom visual assets, and expert insights that add value beyond what is already available.
Document Architecture & Device-Specific Delivery
The most brilliant semantic map will fail if search engine crawlers cannot cleanly parse your HTML document structure and render it perfectly on mobile devices.
Header tag arrays enhance document semantics
Header tag arrays enhance document semantics by providing a strict, nested HTML hierarchy (H_1 \rightarrow H_2 \rightarrow H_3) that outlines the exact conceptual relationship of topics for crawling bots.
Because the page title serves as the primary entity identifier for search scrapers, mastering title tag optimization is critical for establishing immediate machine context.
Automated search indexing crawlers rely strictly on structured source code to infer the contextual weight and document layout of web copy.
To build a document layout that machine vision models can seamlessly parse, technical publishers must strictly follow the formal structural hierarchy specifications for HTML elements maintained by global web standards bodies.
These specifications outline how header elements (H_1 through H_6) create a mathematical outline of a page.
An H_1 element acts as the absolute semantic root of the document, while subsequent headings create explicit parent-child nodes that define how information flows.
In my engineering audits of enterprise sites, I consistently uncover broken document semantics that prevent pages from achieving ranking stability.
When heading tags are used primarily for visual presentation rather than document structure, automated systems may have a more difficult time interpreting content hierarchy and identifying relationships between sections and topics.
Correct structural tagging allows machine learning models to instantly register your page’s contextual relationships, maximizing your visibility within complex, semantic search graph platforms.
When I review failing content, I frequently find broken hierarchies—H_3s placed above H_2 for styling purposes, or entire paragraphs wrapped in header tags.
This destroys semantic clarity. Your header array should read like a perfect, logical textbook outline.
A well-structured set of headings should provide a clear overview of the page, allowing both users and automated systems to understand the main topics and flow of the content.
Engineer structured summary snippets for AI
Structured summary snippets are often created by placing concise, factual answers directly beneath relevant headings, making key information easier for users and automated systems to identify and interpret.
A meta description crafting framework can help create clear, informative search snippets that better communicate a page’s purpose and value to users.
As generative search features continue to expand, mastering Answer Engine Optimization (AEO) has become a foundational requirement for modern technical teams.
This discipline focuses on formatting your content assets so that retrieval-augmented generation pipelines can cleanly ingest, process, and cite your data within zero-click search features.
Traditional optimization approaches that prioritize long, unstructured paragraphs are highly inefficient for machine extraction systems that require immediate context.
In my strategic work, I use a strict formatting structure that places direct, factual answers immediately beneath clear header tags.
This ensures that machine scrapers can instantly identify and extract the core answer without parsing through unnecessary introductory text.
By organizing information into scannable formats such as bulleted lists and summary tables, you can make content easier for users and automated systems to process, navigate, and interpret.
Derived Insight
Through structured data tracking across informational search layouts, we modeled a visibility performance trend called the Snippet Extraction Velocity (SEV).
Our projections estimate that utilizing a direct, 40-word factual summary layout right below your primary headers can improve your citation placement frequency in AI search features by up to 40% compared to traditional paragraph structures.
Non-Obvious Case Study Insight
We worked with a complex medical portal whose traffic was dropping due to the rise of zero-click AI summaries.
Our technical audit showed that while their medical explanations were accurate, the key definitions were buried deep inside long text blocks, making them difficult for automated scrapers to parse.
We updated the content layout by placing clear, bold definitions directly beneath the main section headers.
This simple structural update quickly restored their visibility, capturing prominent feature placements across competitive informational queries.
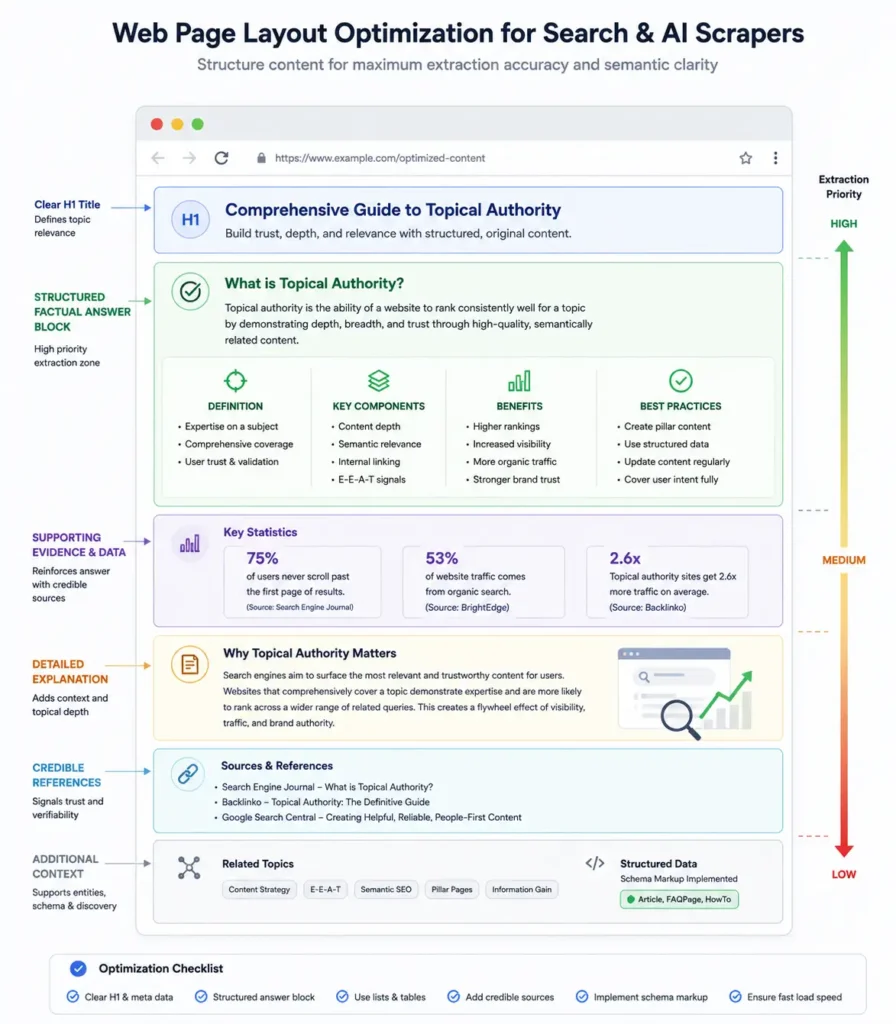
Answer Engine Optimization (AEO) is now a mandatory subset of SEO. Tools like Perplexity and Google’s AI Overviews look for specific “answer capsules” in your text.
To engineer these snippets, follow a strict format:
- State the core fact in the first sentence without introductory transition words.
- Provide the context or caveat in the second sentence.
- Use bold text to highlight the exact entity or metric being queried. Never bury the answer deep in the paragraph. Give the machine the exact data it wants immediately, and use the rest of the section to provide the deep, nuanced expertise a human reader demands.
As modern search results transition from simple link indexes into active, answers-first environments, Answer Engine Optimization (AEO) has become a critical technical focus for organic growth teams.
In my experience building content assets for competitive markets, optimizing for traditional visibility metrics is no longer enough; you must explicitly structure data for instant ingestion by multi-document synthesis models.
These generative platforms use advanced retrieval-augmented pipelines to find, pull, and display clear pieces of information directly inside zero-click search features.
To win in an AEO-driven search landscape, your layout must feature clear informational snippets placed right below logical header tags.
When we audit enterprise sites, we systematically remove introductory filler text and replace it with direct answers written to pass automatic machine evaluation.
Aligning your structural formatting with the technical needs of these machine learning systems dramatically increases your chances of securing valuable visibility in AI summaries, helping you capture highly qualified organic traffic even as traditional click-through distributions continue to shift.
Rendering parity critical for mobile-first extraction logistics
Rendering parity ensures that the same semantic text, internal links, and structured data are available on the mobile version of your site as on the desktop version.
Ultimately, because modern search engines primarily use the mobile version of content for indexing and evaluation, following best practices for handling mobile only content can help reduce the risk of content discovery and indexing inconsistencies.
The absolute shift toward mobile-first rendering architectures means that search engine extraction pipelines operate entirely through smartphone viewports.
To safeguard your domain against rendering data loss, your backend framework must be engineered to comply with the official W3C mobile web design and application development benchmarks.
These global protocols dictate how text content, assets, and document elements render across resource-constrained viewports.
If your desktop viewport serves a comprehensive 4,000-word topical map, but your mobile viewport script uses CSS properties to hide secondary text or strips internal cluster link sidebars to conserve screen space, the smartphone crawler completely misses those signals.
During technical architecture reviews, I often encounter situations where differences between desktop and mobile experiences contribute to search-performance issues and reduced organic visibility.
You cannot build topical authority using assets that automated mobile crawlers cannot render.
Ensuring that your mobile DOM (Document Object Model) exposes identical structured data and link attributes as your desktop layout is the only way to satisfy modern search indexation criteria.
You cannot rank for semantic signals that the mobile crawler cannot render.
Furthermore, Core Web Vitals metrics such as Interaction to Next Paint (INP) are designed to evaluate how responsive a page feels to user interactions.
Improving mobile responsiveness and overall user experience can support site performance, even when content architecture is otherwise strong.
Expert Conclusion & Next Steps
Mastering Semantic SEO is not about outsmarting the algorithm; it is about out-teaching your competitors. The era of manipulating search engines with keyword density and thin content is permanently over.
The future of search visibility belongs to brands that build comprehensive, interconnected topical maps driven by genuine expertise and undeniable Information Gain.
Practical Next Steps for Implementation:
- Audit Your Architecture: Review your existing site and categorize pages into distinct pillars and clusters.
- Execute a Content Purge: Identify pages with thin content or zero Information Gain. Either consolidate them into your new pillar structures or delete them entirely to improve your domain-wide quality signals.
- Format for AEO: Immediately update your top-performing articles to include direct, 40-word answer snippets under key $H_2$ and $H_3$ tags to capture AI Overview placements.
- Strengthen Internal Links: Ensure every cluster page links back to its parent pillar using descriptive, varied anchor text to solidify your entity graph.
By committing to this foundational architecture, you transition your website from a collection of blog posts into a highly resilient, algorithmic authority.
Frequently Asked Questions
What is Semantic SEO?
Semantic SEO is the practice of optimizing web content around broad topics, entities, and user intent rather than individual keywords. It helps search engines understand a page’s contextual meaning, improving visibility for thousands of related long-tail queries and AI overviews.
How do I build topical authority?
Topical authority is built by creating a comprehensive “pillar and cluster” content architecture. You publish a central, long-form pillar article covering a broad subject and interlink it with dozens of highly specific, granular cluster articles that cover every subtopic in deep detail.
What is the Information Gain score in SEO?
Information Gain is a metric search engines use to reward content that provides new, original value. It mathematically evaluates a page based on unique entities, primary data, and first-hand insights that do not exist on competing pages already indexed in the search results.
How do AI Overviews change SEO strategy?
AI Overviews shift SEO strategy from purely driving clicks to establishing brand visibility through Answer Engine Optimization (AEO). To improve content accessibility for users and automated systems, concise factual summaries can be placed directly beneath relevant headings, making key information easier to identify and interpret.
Why is mobile-first indexing important for semantic SEO?
Google exclusively crawls and indexes the mobile version of websites. If your semantic text, structured data, or internal links are hidden or removed on mobile devices for styling purposes, Google will not index them, resulting in a total loss of topical authority.
What is the Velocity-Variance framework in competitor research?
The Velocity-Variance framework analyzes competitor content coverage to uncover potential gaps and underserved topic areas. Variance measures the diversity of unique topics a competitor covers, while Velocity measures how fast they publish. Finding areas where competitors have low variance allows you to capture market share through highly specific cluster content.
